-
 UTF-8 Datei per FTP richtig verarbeiten UTF-8 Datei per FTP richtig verarbeiten
Schönen guten Tag zusammen,
ich habe ein kleines Problem und hoffe hier könnt mir weiterhelfen.
Folgende Situation: Ich habe ein .txt Datei in dem Zeichen aus anderen europäischen Ländern (polnische, tschechische, ..) enthalten sind. Sobald ich diese per FTP (Übertragungsart: Binär) auf die AS400 übertrage und diese im IFS über die Auswahl "5=Anzeigen" anschauen sind die Zeichen verstümmelt und werden nicht richtig dargestellt.
Meine Vermutung es liegt an der CCSID, die Datei hat nach der Übertragung auf die AS400 die CCSID 819.
CCSID . . . . . . . . . . . . . . . . : 819
Verdeckte Datei . . . . . . . . . . . : Nein
PC-Systemdatei . . . . . . . . . . . . : Nein
Lesezugriff . . . . . . . . . . . . . : Nein
Mein Ziel: Die Sonderzeichen sollen erhalten bleiben, den diese Informationen soll später in eine Tabelle einfließen und das darf nur passieren wenn Sie nicht mehr nach der Übertragung verfälscht werden.
-
In diesem Fall musst du nach dem FTP per
CHGATR OBJ('/MyFile')
ATR(*CCSID)
VALUE(1208)
die CCSID anpassen. In den FTP-Attributen (CHGFTPA) kann nur generell eine CCSID für jede Datei gesetzt werden.
-
Danke @Fuerchau
Leider hat es nicht ganz geklappt.
original Text:
Code:
Jeszcze Polska nie zginęła,
Kiedy my żyjemy.
Co nam obca przemoc wzięła,
Szablą odbierzemy.
mit Auswahl 5
Code:
Jeszcze Polska nie zginÄ Å a,
Kiedy my żyjemy.
Co nam obca przemoc wziÄ Å a,
SzablÄ odbierzemy.
Nach dem Befehl CHGATR:
Code:
Jeszcze Polska nie zgin a,
Kiedy my yjemy.
Co nam obca przemoc wzi a,
Szabl odbierzemy.
-
Die korrekte Anzeige funktioniert an einem 273-Terminal ggf. nicht korrekt.
Du kannst nur die Hex-Werte vergleichen, ob diese korrekt sind.
Für die Anzeige muss du die Datei dann mit z.B. Notepad++ öffnen, also einer unicodefähigen Anwendung.
-
@SourceCoder
hat deine 5250 Session denn auch die entsprechende CCSID?
Also 870 oder 1153 sofern die Datei polnisch und nicht UTF-8 ist (Die original Datei sieht aber schwer danach aus).
Ansonsten wie Fuerchau schon schrieb... die Hex-Werte vergleichen.
(Anzeige der Datei schon auf der 5250 Session, aber im Hex-Modus)
------------------
Das die original Datei UTF-8 ist hab ich dann jetzt dem Thema auch mal entnommen ;-)
-
Hab mal meine Session auf 870 gestellt, leider ohne erfolg für die Anzeige. Was ich mich auch wundere in allen drei Fällen sind die Hex-Werte identisch.
original Text:
Code:
4A 65 73 7A 63 7A 65 20-50 6F 6C 73 6B 61 20 6E
69 65 20 7A 67 69 6E C4-99 C5 82 61 2C 0D 0A 4B
69 65 64 79 20 6D 79 20-C5 BC 79 6A 65 6D 79 2E
...
mit Auswahl 5 auf der Maschine
Code:
4A 65 73 7A 63 7A 65 20-50 6F 6C 73 6B 61 20 6E
69 65 20 7A 67 69 6E C4-99 C5 82 61 2C 0D 0A 4B
69 65 64 79 20 6D 79 20-C5 BC 79 6A 65 6D 79 2E
...
Nach dem Befehl "CHGATR":
Code:
4A 65 73 7A 63 7A 65 20-50 6F 6C 73 6B 61 20 6E
69 65 20 7A 67 69 6E C4-99 C5 82 61 2C 0D 0A 4B
69 65 64 79 20 6D 79 20-C5 BC 79 6A 65 6D 79 2E
...
Original Datei ist UTF-8
-
Also die Hexwerte sind ja identisch, so dass es eben keine Verfälschung von Daten gibt.
Dies ist schon mal was wert.
Vom Inhalt sind Zeichen die mit x'Cn' anfangen UTF8-Zeichen, z.B. C499, C582.
Durch das CHGATR wird nun die CCSID der Datei korrekt gesetzt, so dass die Zeichen korrekt interpretiert und z.B. in eine Datenbank (NCHAR, NVARCHAR) geschrieben werden können.
Bei deiner Anzeige am 5250 können nur Zeichen korrekt dargestellt werden, die der CCSID des Jobs und des Terminals entsprechen.
Um also polnisch sehen zu können, musst du Job und Terminal auf 870 stellen, für Deutsch gilt dann 273/1141 usw.
Zwischen Job und Terminal gibts keine Codeanpassung mehr, das muss einfach passen.
Bei der CCSID 819 ging das System von einem SBCS-Zeichensatz aus und hat dies simple in EBCDIC (z.B. 273) umgewandelt. Bei einer CCSID 1208 wird von UTF-8 in UCS2 umgewandelt und dann in die SBCS-Zeichen deines Jobs. Nicht darstellbare Zeichen gehen dabei verloren.
Dashalb darf man UTF-8/UCS2-Daten an einem SBCS-Terminal nie bearbeiten!
UCS2-Terminals in 5250 gibt es leider nicht, da ein Job alles als SBCS ans Terminal schickt.
Selbst wenn man ein UCS2-Feld in einer DSPF definiert, kann man nur passend zur Codepage Zeichen sehen und eingeben.
Um mit UCS2 (konvertiert aus UTF8) korrekt umzugehen schließt dies das 5250-Terminal aus.
-
Fuerchau hat das mal schön ausführlich beschrieben! :-)
@SourceCoder
Die Frage ist auch vielleicht... was soll später mit den Daten passieren?
Wenn du dir die Daten auf einer 5250 Session anzeigen lassen magst:
- deine Beispieldaten (die Text Datei) von UTF-8 in iso 8859-2 konvertiert
- dann auf die i5 per ftp übertragen
- die CCSID auf 912 (8859-2) gesetzt
- ne 5250 Sitzung unter 870 in nem SBS (also Job) 870 gestartet
- die Datei anzeigen lassen
Die hex-Werte sind natürlich nicht mehr die gleichen wie in der Ursprungsdatei.
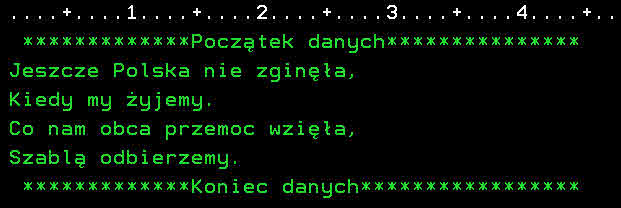
-
Die Textanzeige einer UTF-8-Datei sollte ohne jegliche Konvertierung auf dem korrekten Terminal funktionieren.
Dies sieht man ja an obigem Beispiel, dass bei 819 alles angezeigt wird und bei 1208 ungültige Zeichen ausgeblendet werden.
-
probier ich doch mal aus :-)
und... funktioniert!
Wenn du dir die Daten auf einer 5250 Session anzeigen lassen magst:
- Datei per ftp auf die i5 übertragen
- die CCSID auf 1208 gesetzt
- ne 5250 Sitzung unter 870 in nem SBS (also Job) 870 gestartet
- die Datei anzeigen lassen
-
Guten Morgen und danke für die tollen Antworten.
Also mein Ziel ist es: Die Informationen mit den richtigen Zeichen in die Datenbank zu speichern und dann sollen diese Informationen später auf ein Label gedruckt werden.
Also ich habe es nun hinbekommen das die Zeichen auch richtig dargestellt werden, folgende Schritte habe ich getan.
1. CHGATR OBJ('/MyFile') ATR(*CCSID) VALUE(1208)
2. CHGJOB JOB() LANGID(PLK) CCSID(870)
3. Session Einstellung: AS/400 code page von 273 auf 870 geändert und Encoding von Windows OS default auf Windows-1250 (Mitteleuropäisch)
Wenn ich das richtig verstanden habe werden die Werte richtig in die DB übernommen wenn ich vorher über den Befehl "CHGATR" die CCSID auf "1208" geändert habe. Und die Schritte 2 und 3 sind nur für die reine Anzeige relevant richtig?
Das mit Schritt 1 sollte ja auch keine Probleme bereiten wenn auf einmal z.B tschechische Zeichen in dieser Datei vorhanden sein sollten oder?
-
In die Datenbank bekommst du die Daten nur dann vernünftig, wenn die Felder ebenso UCS2 sind:
DDS Typ G, CCSID 13488
SQL N[VAR]CHAR(xx)
Im Programm sind die Variablen dann vom Typ "C".
Beim Drucken allerdings hört der Spaß fast wieder auf:
AFPDS = Dies geht, wenn du z.B. PDF-Ausgabe wählst, kann in der PRTF ein Typ-G-Feld mit einem TrueTypeFont verwendet werden.
Bei anderen Ausdrucken (SCS, lokalen Druckern) müssen die Daten in die korrekte CHRID für die PRTF ausgegeben werden. Die CHRID wird beim CRTPRTF/OVRPRTF angegeben.
Die Daten zum Drucker unterliegen, ebenso wie beim Display, keiner Codewandlung.
D.h., auf Grund der CHRID wird im Drucker die Codepage (850=Deutsch, 852=Osteuropa, ...) ausgewählt. Ist diese nicht vorhanden, wird Schrott gedruckt.
Wenn du z.B. einen Zebra-Drucker einsetzt, musst du die ZPL-Codes der Codepage kennen und die Daten passend in der EBCDIC-CCSID an den Drucker geben.
Im Programm kann man per API (dynmischer) oder auch per SQL (leider nur statisch) Codewandlungen durchführen, dazu sollte die Daten in einer "C"-Variablen vorliegen:
SQL: exec sql set : MyChar870 = cast(: MyCVar as char(nn) ccsid 870);
Leider lässt sich das so nicht per dynamischem SQL ausführen.
Oder du liest die Daten mittels dynamischem Cursor direkt in der passenden CCSID ein.
Wie du siehst, leider nicht ganz so einfach, da du im Vorhinein wissen musst, welche CCSID deine Daten haben um dann entsprechend für die Ausgabe reagieren zu können.
D.h., dass du am besten deine Daten mit einem eigenen Zusatzfeld und der Quell-CCSID speicherst.
Similar Threads
-
By dschroeder in forum NEWSboard Programmierung
Antworten: 13
Letzter Beitrag: 13-07-16, 14:23
-
By Joe in forum IBM i Hauptforum
Antworten: 5
Letzter Beitrag: 06-08-15, 10:45
-
By lemmi in forum IBM i Hauptforum
Antworten: 8
Letzter Beitrag: 26-02-03, 23:56
-
By DiBagger in forum IBM i Hauptforum
Antworten: 2
Letzter Beitrag: 13-09-02, 12:41
-
By Neurohr in forum IBM i Hauptforum
Antworten: 10
Letzter Beitrag: 12-07-02, 23:53
 Berechtigungen
Berechtigungen
- Neue Themen erstellen: Nein
- Themen beantworten: Nein
- You may not post attachments
- You may not edit your posts
-
Foren-Regeln
|
Erweiterte Foren Suche
Google Foren Suche
Forum & Artikel
Update eMail
AS/400 / IBM i
Server Expert Gruppen
Unternehmens IT
|
Kategorien online Artikel
- Big Data, Analytics, BI, MIS
- Cloud, Social Media, Devices
- DMS, Archivierung, Druck
- ERP + Add-ons, Business Software
- Hochverfügbarkeit
- Human Resources, Personal
- IBM Announcements
- IT-Karikaturen
- Leitartikel
- Load`n`go
- Messen, Veranstaltungen
- NEWSolutions Dossiers
- Programmierung
- Security
- Software Development + Change Mgmt.
- Solutions & Provider
- Speicher – Storage
- Strategische Berichte
- Systemmanagement
- Tools, Hot-Tips
Auf dem Laufenden bleiben
|

![[NEWSboard IBMi Forum]](images/duke/nblogo.gif)
 [User]
[User]


 Mit Zitat antworten
Mit Zitat antworten
Bookmarks