von Denis Kohl
Unter allen Unix-Versionen werden Daten unabhängig von ihrer Bedeutung in Dateien abgelegt. Das führt dazu, dass man nicht unbedingt auf den ersten Blick erkennt, was man vor sich hat. Dieser Artikel behandelt die Werkzeuge, die es uns erlauben, einen Überblick über die Dateien zu bekommen.

c CC0
Ist es eine Textdatei, eine komprimierte Datei oder ein ausführbares Programm? An vielen Stellen behilft man sich mit Endungen. Zum Beispiel .sh für Shellscripte oder .zip für komprimierte Daten. In der Realität kann man sich aber nicht immer darauf verlassen.
Durch die Vielzahl der dadurch entstehenden Möglichkeiten ging man unter Unix seit den 70er Jahren den Weg, viele kleine, variabel miteinander kombinierbare Werkzeuge zu erstellen.
Dieser Artikel behandelt die Werkzeuge, die es uns erlauben, einen Überblick über die Dateien zu bekommen.
Die Befehle, die wir uns näher ansehen werden, sind:
cmp - Byte-weises Vergleichen von Dateien diff - zeilenweiser Dateivergleich grep - Durchsuchen von Dateien nach Mustern auf Zeilenebene
Dateien im IFS kann man grob in drei Gruppen aufteilen: ausführbare und nicht ausführbare binäre Dateien, sowie Textdateien.
Ausführbare binäre Dateien sind kompilierte Programme. Nicht ausführbare binäre Dateien sind beispielsweise Bilder, MP3 Files, Filme, aber auch komprimierte oder verschlüsselte Dateien.
Type\Nutzung Ausführbar Lesbar (Editor) Textdatei - + Script (Perl, Python, Bash, sh) + + Bilder, Filme, MP3, komprimierte Datei, usw. - - Programme + -
Textdateien stellen im alltäglichen Arbeiten die größte Herausforderung dar.
Um das umfassend zu verstehen, muss man sich kurz den Aufbau dieser Dateien ansehen. Wie in allen anderen Formen von binär gespeicherten Daten sind auch hier die Daten in Mustern von 1 und 0 gespeichert. Erst eine Kodierungstabelle ermöglicht es dem Anzeigeprogramm, Buchstaben, Zahlen und weitere Zeichen darzustellen.
Die bekannteste Kodierung ist ASCII. Hierbei werden die Zeichen einer amerikanischen Tastatur in 7-bit kodiert.
Eine weitere sehr bekannte und die im Moment am weitesten verbreitete Kodierung ist UTF-8. Hierbei können fast alle weltweit existierenden Schriftzeichen kodiert werden. Dabei benötigt man allerdings 1-2 Byte um die Zeichen zu speichern.
Im OS400 kommen noch die IBM CCSID (Coded Character Set Identifier) -Kodierungen hinzu. Diese kann man als Vorläufer der UTF-8, UTF16 und UTF-32-Kodierungen sehen.
Bei der CCSID-Kodierung wird ein 16-bit Word benutzt, um ein Zeichen zu kodieren.
Die Kodierung ist nach Ländergruppen aufgeteilt, beispielsweise bildet CCSID819 die Zeichen für Mitteleuropa ab (kompatibel zu Latin-1, ISO8859-1). CCSID932 kodiert die japanische Alltagsschrift. CCSID 1208 ist kompatibel zu UTF-8.
Deshalb kann man über die OS400 CCSID alle bekannten Kodierungen darstellen. Das führt dazu, dass in der Regel die Programme im IFS in der Lage sind, Daten in der richtigen Form zu öffnen.
Wenn man die Dateien in der falschen Form öffnet, hat man immer einzelne Zeichen, die nicht sauber dargestellt werden.
Mit diff kann man sehen, dass es sich hier nicht um identische Dateien handelt. Auch, wenn sie auf den ersten Blick gleich aussehen.
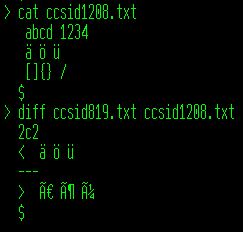
Abbildung 1
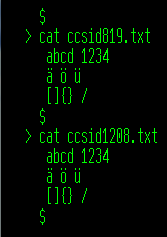
Abbildung 2
Wenn man mit ssh (Secure Shell) auf die OS400-Maschine zugreift, muss man darauf achten, dass man die Kodierung richtig einstellt. Andernfalls kann die falsche Kodierung das Arbeiten erschweren.
Der erste Befehl ist diff – Difference. Dieser unterscheidet sich allerdings deutlich von den heute unter UNIX und Linux verfügbaren Befehlen. Die Aufgaben des Unix diff werden unter OS400 von diff und sdiff erfüllt. Die Idee dieser Befehle ist es, auf character-basierende Dateien zeilenweise zu vergleichen.
Unter QSH teilen sich die Funktionen zum einen in sdiff. Hier kann man zwei Dateien öffnen und vergleichen. Die Dateien werden nebeneinander dargestellt. So dass man recht komfortabel die Unterschiede erkennen kann.
Dies kann sinnvoll sein, wenn man unterschiedliche Versionen eines Scripts oder einer Logdateien vergleichen möchte.
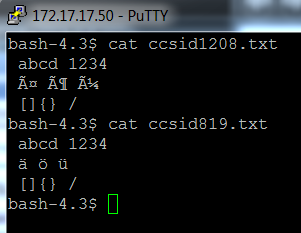
Abbildung 3
Wie in Abb 5 schön zu erkennen ist, werden Zeilen als unterschiedlich erkannt, wenn sie sich schon in einem Zeichen unterscheiden. Gerade beim Verwalten von Skripten kann dies sehr nützlich sein. Oft werden hier Änderungen schnell auf dem Produktive System gemacht. Hier kann durch einen Vergleich mit der Masterdatei schnell herausgefunden werden, was geändert wurde und warum es jetzt Unterschiede bei der Ausführung der Skripte gibt.
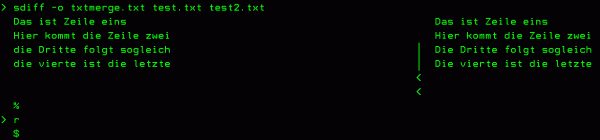
Abbildung 4
Zum anderen kann der eigentliche diff-Befehl genutzt werden, um sich anzeigen zu lassen, in welchen Zeilen sich etwas geändert hat.
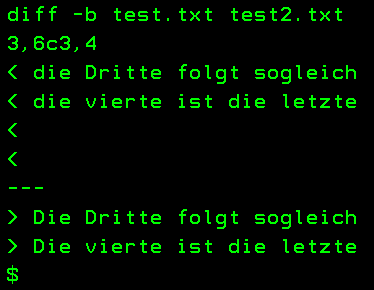
Abbildung 5
Dies kann bei großen Dateien, mit nur geringen Unterschieden, sehr nützlich sein.
Welche Befehle man wirklich nutzt, hängt von Vorlieben und Erfahrung ab.
Die Anwendung von diff ist
diff -b <Datei1> <Datei2>
Die option -b sorgt dafür, dass Leerzeichen igoriert werden.
Nicht alle Dateien sind als Textdatei kodiert. Daher benötigen wir einen weiteren Befehl, um Dateien auf unterster Ebene zu vergleichen.
Hier hilft uns der Befehl cmp – compare. Das ist ein Programm, das auf Byte-Ebene Dateien vergleicht. Dies kann interessant sein, wenn man binäre Dateien findet, die den selben Namen haben, man sich jedoch nicht sicher ist, ob die Dateien identisch sind. Dies kann zum Beispiel nach der Installation eines Updates nötig sein.
Ein anderes Beispiel ist, wenn man mehrere gleichnamige Dateien findet, die sich aber an unterschiedlichen Stellen im Dateisystem befinden. Sollten sie identisch sein, kann man die Kopien löschen und auch Links (Verweise) ersetzen.
Der Befehl cmp vergleicht die Dateien Byte-weise und gibt an, welche Zeichen in welcher Zeile sich unterscheiden.
Die Anwendung ist
cmp <Datei1> <Datei2>
Die Datei 1 ist dabei die Basis. In der Ausgabe erscheinen dann die Zeilen und Zeichen die sich unterscheiden.
Weiterhin kann man hier auch feststellen, ob und wie eine Datei gewachsen ist, indem man die aktuelle Inkarnation der Datei mit einer früheren Inkarnation aus einer Sicherung vergleicht.
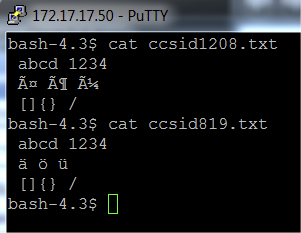
Abbildung 6
Dies kann bei Datenbank-, oder datenbankähnlichen Dateien interessant sein, beispielsweise SQLite.
Der dritte Befehl den wir uns hier ansehen wollen ist grep.
Hier geht es nicht darum, einen Vergleich anzustellen, sondern nach einem konkreten Inhalt zu suchen. Mit grep ist es möglich, eine Datei zeilenweise zu durchsuchen. Ziel ist es, mehr über den Inhalt der Datei zu lernen. Ein Beispiel wäre das Durchsuchen einer Logdatei. Nehmen wir an, Sie haben einen, wie auch immer gearteten, Java Application Server auf Ihrem System installiert. Dieser wird im IFS eine Logdatei ablegen.
Jetzt gibt es einen Störfall. Nun können Sie grep nutzen, um sich die Dateien anzeigen zu lassen, die die Fehlermeldung enthalten. Grep kann Ihnen hier folgende Fragen beantworten:
- Was genau ist die Fehlermeldung in ganzer Länge?
- Wann gab es diesen oder einen ähnlichen Störfall?
- Wie oft gab es diesen Störfall?
In Abbildung 7 sehen wir zwei Anwendungen von grep.
Der Aufruf von grep erfolgt wie folgt:
grep <Muster> <Datei>
Hierbei soll grep die Datei nach dem Muster durchsuchen und dann die Zeilen ausgeben, die dem Muster entsprechen.
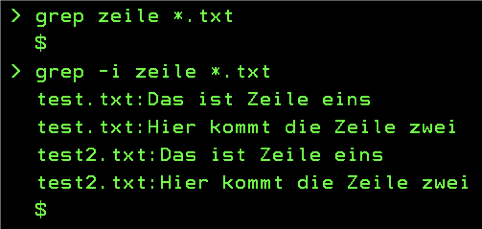
Abbildung 7
Dies kann man nicht nur auf Logdateien anwenden, sondern auf jede Art von Datei.
Auch kann man das Ergebnis eines anderen Kommandos umleiten, so dass man grep als Filter für die vorherige Ausgabe benutzen kann.
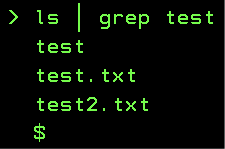
Abbildung 8
In Abbildung 8 wird das an dem Beispiel gezeigt:
ls - List Files umgeleitet nach grep.
Der Befehl ls gibt die Namen aller Dateien im Verzeichnis aus. Das Pip-Symbol leitet diese Ausgabe zu grep um. Der grep-Befehl filtert dann alle Dateien aus, die nicht das Muster, in diesem Fall test, enthalten.
Hier zeigt sich die Flexibilität, die man durch die Unix Werkzeuge bekommt. Hierbei muss man allerdings noch auf ein Problem eingehen, das immer wieder auftritt, wenn Daten von einem System auf ein anderes übernommen werden. Die Textdateien können in unterschiedlichen Kodierungen abgelegt sein.
Dieses Problem wird sichtbar, wenn man ein Verfahren wie ssh nutzt, um auf den IBM Host zuzugreifen oder aber eine Datei mit einem Editor öffnet.
Über den Autor
Lars Denis Kohl absolvierte das Studium der Informatik an der FU-Berlin und ist seit 2003 als freier Dozent tätig. Mit Schwerpunkt 2007-2011 ist er Tutor im Rahmen der IBM Akademische Initiative Deutschland sowie seit 2010 freier Entwickler und Projektmanager für mobile Anwendungen sowie Trainer bei LDK Beratung.
Ähnliche Artikel:
 QShell Utilities – Nützliche Werkzeuge in IBM i Die QShell, angekündigt 1998 als Bestandteil von OS/400 V4R2, ist seit etwa 20 Jahren für IBM i Anwender verfügbar, wird aber nach meiner Erfahrung noch von zu wenigen Administratoren wirklich…
QShell Utilities – Nützliche Werkzeuge in IBM i Die QShell, angekündigt 1998 als Bestandteil von OS/400 V4R2, ist seit etwa 20 Jahren für IBM i Anwender verfügbar, wird aber nach meiner Erfahrung noch von zu wenigen Administratoren wirklich… FlashCopy und IBM i In immer mehr Kundenumfeldern wird das Thema Offline-Backup zunehmend schwieriger, weil entsprechende Zeitfenster nicht zur Verfügung stehen. Bei immer größeren Datenmengen ist auch ein traditioneller Restore von einem Band in…
FlashCopy und IBM i In immer mehr Kundenumfeldern wird das Thema Offline-Backup zunehmend schwieriger, weil entsprechende Zeitfenster nicht zur Verfügung stehen. Bei immer größeren Datenmengen ist auch ein traditioneller Restore von einem Band in… Legacy-Anwendungen: Auf Bewährtem aufbauen Teil 3 Man kann Programme schreiben, die Anwendungs-Maps dafür nutzen, um den Source Code zu analysieren und nach Hinweisen auf Foreign-Key-Beziehungen zwischen den einzelnen Feldern der Anwendung zu ermitteln. Bei großen Anwendungen…
Legacy-Anwendungen: Auf Bewährtem aufbauen Teil 3 Man kann Programme schreiben, die Anwendungs-Maps dafür nutzen, um den Source Code zu analysieren und nach Hinweisen auf Foreign-Key-Beziehungen zwischen den einzelnen Feldern der Anwendung zu ermitteln. Bei großen Anwendungen…