© tom-kirchgaessner.de und Jason Leung
von Manfred Sielhorst, Benjamin Walter
Gerade im Hinblick auf den Wechsel zu IBM ACS und IBM RDi als Werkzeuge für die Administration und die Entwicklung mit der Verlagerung von Quellen ins IFS hat dies eine besondere Bedeutung in Bezug auf die Abhängigkeiten und die Aktualität: „Passt die angezeigte Information im Client zum benutzten IBM i System?“ Nicht nur die singuläre Analyse eines einzelnen Befehls im Terminal, sondern auch die komplexe Auswertung einer gesamten IBM i Infrastruktur mit allen Kundenanpassungen und Erweiterungen, ist eines der Ziele der semantischen Analyse im Semantic Data Store.
Inhaltsverzeichnis dieses Artikels
Inhaltsverzeichnis 24
Teil 3 — Analyse von IBM i Befehlen 25
Knowledge-Engineering 25
N-Gram-Analyse von Befehlen 26
Analyse der Systembefehle 27
Gruppierung nach Namenskomponenten 27
Bedeutungskonflikte ergründen 28
Fazit 30
Ausblick 30
Literatur 31
Autoren 31
Teil 3 — Analyse von IBM i Befehlen
Die Teile 1 und 2 haben sich mit der Relevanz von Befehlen für Benutzer auseinander gesetzt und das technischen Hintergrundwissen zu semantischen Analysen vorgestellt.
Darauf aufbauend wird hier eine Methodik vorgestellt mit der eine Ontologie modelliert wird. Dazu werden mit Hilfe einer N-Gram-Analyse der Namen der Systembefehle Fakten gewonnen, die über die Modellierung in die Ontologie instantiiert und dann mit Fachwissen kombiniert werden können.
Knowledge-Engineering
Bevor eine Ontologie sinnvoll modelliert werden kann braucht es Wissen. Die Disziplin des Erfassens von Wissen nennt sich Knowledge-Engineering.
Der in dieser Arbeit verwendete Ansatz orientiert sich an der Erfassung von Wissen wie im Artikel von Jackson (s. Abb. 3.1). Dabei wird mit den Schritten Identifikation (I), Konzeptualisierung (K) und Formalisierung (F) der Prozess des Ontology-Engineering (O), dem Sammeln und Modellieren einer zugehörigen Ontologie aus Wissen, mit folgenden Ansätzen angewandt.
Die Formalisierung (F) erfolgt mit der OWL2, was in Teil 2 vorgestellt wurde.
Die Arbeit von A. Textor [5] zeigt gängige Methodiken und deren Schwerpunkte zur Erstellung von Ontologien auf. Für das Ontology-Engineering (O) präsentiert er drei prinzipielle Ansätze der Modellierung:
o1) Der Ansatz von oben (top-down) beginnt mit den generellsten Konzepten und arbeitet sich zu den spezifischeren hinunter. Dieser Ansatz ist für das gegebene Problem ungeeignet, da die spezifischen Konzepte bereits bekannt und gesetzt sind, aber die allgemeineren erst erarbeitet werden müssten.
o2) Das gleiche trifft auch auf den Ansatz aus der Mitte (middle-out) zu, bei dem mit den Kernkonzepten gestartet wird und gleichzeitig generalisiert und spezialisiert wird.
o3) Der Ansatz von unten (bottom-up) beschreibt das Vorgehen mit den spezifischen Teilen der Ontologie zu beginnen und von da Stück für Stück zu generalisieren. Hierdurch reduziert der Ansatz die Allgemeingültigkeit der Ontologie, was aber im aktuellen Kontext gewünscht ist.
Der Ansatz o3) wurde gewählt, da es sich hierbei um einen problemfokussierten Ansatz handelt, mit dem domänenspezifische Lösungen sehr gut abgebildet werden können und da wie bereits erwähnt die spezifischen Konzepte bereits bekannt sind.
Zum Erfassen der relevanten Konzepte (K) einer Ontologie bietet Mike Uschold [4] einen vier-stufigen Prozess:
”By ontology capture, we mean:
k1) identification of the key concepts and relationships in the domain of interest, i.e. scoping
k2) production of precise unambiguous text definitions for such concepts and relationships
k3) identification of terms to refer to such concepts and relationships
k4) agreeing on all of the above“
Das Identifizieren (I) der relevanten Konzepte und Beziehungen der IBM i Infrastruktur aus Schritt k1) ist für das weitere Vorgehen essentiell. Schritt k2) wurde in Gesprächen mit Experten diskutiert. Der Schritt k3) ist bereits teilweise durch den gewählten bottom-up Ansatz und durch gesetzte Termini der IBM i Umgebung erfolgt. Schritt k4) schließt mit der initialen Modellierung ab.
Folglich befasst sich der nächste Abschnitt mit der Identifikation und Modellierung relevanter Konzepte und Beziehungen aus der IBM i Infrastruktur.
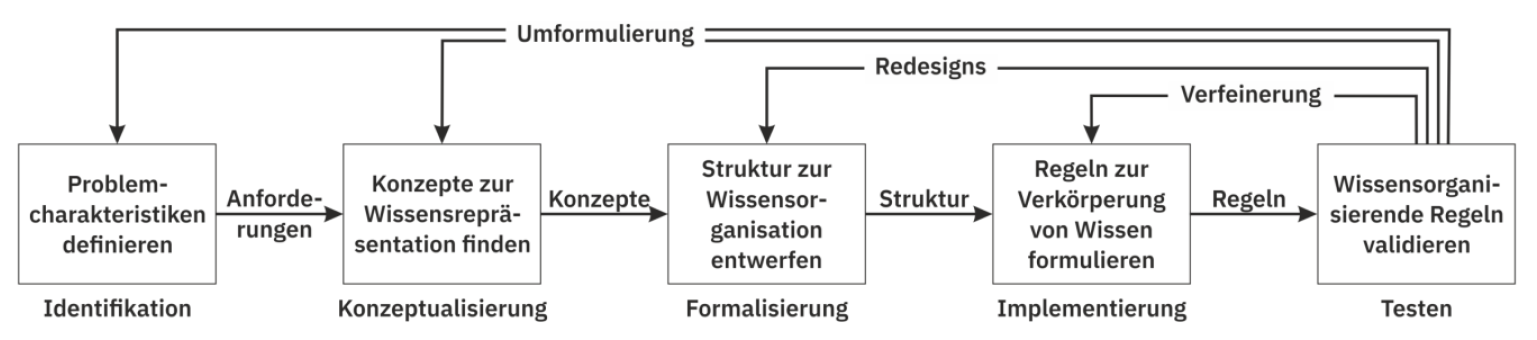
Abb 3.1: Erfassung von Wissen nach Jackson, überarbeitete Darstellung [13]
N-Gram-Analyse von Befehlen
Als Beispiel für die zu modellierende Ontologie werden die auf der IBM i Infrastruktur verfügbaren Befehle gewählt.
Dabei soll analysiert werden, ob Befehle anhand ihres Namens in Gruppen eingeteilt werden können.
Um häufig auftretende Bezeichner zu finden eignet sich eine sogenannte N-Gram-Analyse. Dabei werden häufig auftretende Ausschnitte aus den Befehlsnamen gezählt. Bei der N-Gram-Analyse wird ein Befehlsname in alle möglichen Kombinationen variabler Länge zerlegt und die Vorkommnisse gezählt.
Bezeichnet L die Wortlänge, so ist die Anzahl der entstehenden N-Gramme definiert als:

Siehe hierzu Tabelle 3.1 für eine Zerlegung am Beispiel des Befehlsnamens WRKCMD.
N-Gram Zerlegung für WRKCMD

Tab. 3.1
1-Gramme sowie 2-Gramme liefern durch ihre Häufigkeit kaum Aufschluss über vorkommende Gruppen. Häufig auftretende 3-Gramme oder 4-Gramme hingegen sind bereits starke Indikatoren für sich wiederholende Strukturen in den Befehlsnamen.
Zunächst wird eine Datenbasis geschaffen auf der die Analyse erfolgen kann.
Mit den Befehlen
DSPOBJD(*ALL/*ALL) OBJTYPE(*CMD) OUTFILE(CMDOUT)
DSPOBJD(*ALL/*ALL) OBJTYPE(*MENU) OUTFILE(MENUOUT)
wird eine Liste mit allen Befehlen und allen Menüs abgerufen, die auf dem System existieren und jeweils in eine Ausgabedatei geschrieben werden (OUTFILE). Danach erfolgt die N-Gram-Analyse zu diesen Ausgabedateien.
Die Tabellen 3.2 und 3.3 zeigen die jeweils 20 häufigsten 3-Gramme und 4-Gramme, sowie die jeweilige Anzahl der Vorkommnisse. Für die Analyse wurden insgesamt 2270 Systembefehle gefunden und ausgewertet.
Die Häufigkeit von mehr als 20 ist hier ein starker Indikator für eine Gruppierung, welche sich aus den Befehlsnamen ableiten lässt. Die Analyse zeigt, dass in den gegeben Daten sich wiederholende Strukturen zu finden sind.
Als besondere Herausforderung gestaltet sich im Verlauf der Analyse das Ableiten der Bedeutung. Dies ist ohne weiteres Expertenwissen oder weitere Kontextanalysen nicht möglich.
Durch die Texte zu den Objekten und die verfügbare Online-Hilfe und Dokumentation kann dies weitgehend automatisiert oder für die Beurteilung unterstützt werden.
Die 20 häufigsten 3-Gramme der Systembefehle
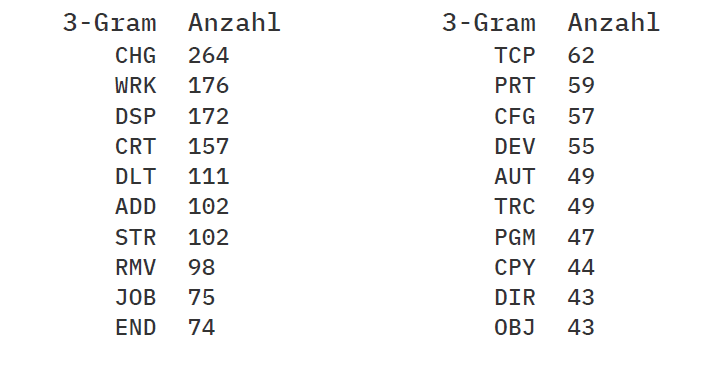
Tab. 3.2
Die 20 häufigsten 4-Gramme der Systembefehle

Tab. 3.3
Analyse der Systembefehle
Um weitere Ausprägungen zu identifizieren folgt eine Analyse der Ist-Situation, welche von Expertenwissen unterstützt wird.
Gruppierung nach Namenskomponenten
Durch Expertenwissen und die N-Gram-Analyse aus Abschnitt 3.2 ist bekannt, dass sich die Befehlsnamen bereits nutzen lassen, um semantische Gruppen abzuleiten. Die Namen sind überwiegend abgekürzte zusammengesetzte Bezeichner hinter denen sich Aktionen oder Objekte verbergen, die sich als Konzepte in der Ontologie eindeutig modellieren lassen.
Daher ist es das Ziel eine Gruppierung der Befehle anhand ihres Namens vorzunehmen, um später explizit danach suchen zu können.
Bei der allgemeinen Betrachtung der Befehlsnamen zeigt sich, dass Befehle typischerweise aus zwei Komponenten zusammengesetzt sind.
In Abb. 3.2 am Beispiel von DSPOBJD werden die beiden Komponenten klar sichtbar.
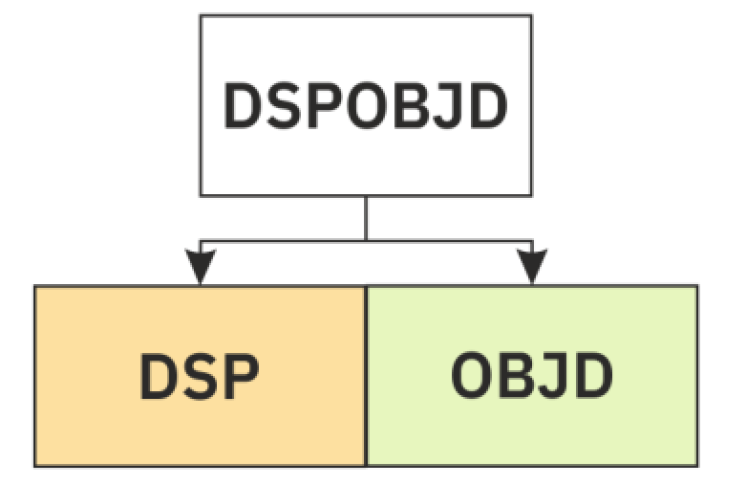
Abb. 3.2: DSPOBJD Komponentenanalyse
Die erste Komponente bezieht sich auf eine Aktion. In diesem Falle DSP für ‘Display‘. Dafür werden die ersten drei nicht Vokale des Befehlsnamens genutzt. Weitere übliche Aktionen sind zum Beispiel WRK für ‘Work‘ oder STR für ‘Start‘.
Die zweite Komponente bezieht sich oftmals auf einen speziellen Objekttyp. In diesem Falle OBJD für ‘Object Description‘.
Weitere übliche Objektbeziehungen die in den Namen auftauchen sind PGM für ‘Programm‘ oder JOB (s. Tab. 3.2).
Die Länge der Komponenten variiert und teilweise ist eine eindeutige Zuordnung nicht möglich. Exemplarisch wird die Namenskomponente QRY betrachtet: die Befehle QRYDST sowie WRKQRY enthalten beide diesen Bestandteil.
Im ersten Fall wird QRY als Aktion (etwas Abfragen) genutzt, im zweiten Fall als Objektrelation (arbeite mit Abfragen).
Damit ist bei den beiden Befehlen die Bedeutung von QRY nicht eindeutig und es existieren folglich Mehrdeutigkeiten bei der Zuordnung. Für diese Fälle wird weiteres Hintergrundwissen benötigt, etwa die Objektattribute oder der Beschreibungstext.
In einem nächsten Schritt wird die Datenbasis um die Liste aller Systemmenüs, die sich auf Befehle beziehen erweitert.
Diese Menüs beginnen üblicherweise mit CMDxxx und sind somit leicht zu identifizieren. Die Existenz eines Menüs zu einer Komponente des Namens eines Befehls (z.B. CMDWRK) gibt einen Hinweis darauf, dass die Komponente im Kontext der IBM i eine vordefinierte Gruppierung darstellt.
Bedeutungskonflikte ergründen
Aus dieser manuellen Analyse können drei Mengen an initialen Gruppierungen der Befehle auf Basis einer Einteilung nach diesen Teilen der Namen abgeleitet werden. Die Menge der Gruppen, welche auf Aktionen (A) basieren, die Menge der Gruppen, welche auf Objektrelationen (O) basieren und die Menge der Gruppen, welche auf einer Zuordnung zu einem Befehlsmenü (B) basieren.

Tab. 3.4
Für Details zu den vorgenommenen Einordnungen der 2270 Befehle findet sich der Ausschnitt für Befehle mit CMD im Namen in Tabelle 3.4.
Aus diesen drei Mengen ergibt sich insgesamt für alle Befehle folgendes Venn-Diagramm (s. Abb. 3.3), in dem die Anzahl der Gruppen basierend auf Namensteilen dargestellt wird, wobei in jeder dieser Gruppen eine Vielzahl von Systembefehlen zugeordnet sein kann (vgl. Tab. 3.9 – 3.11)
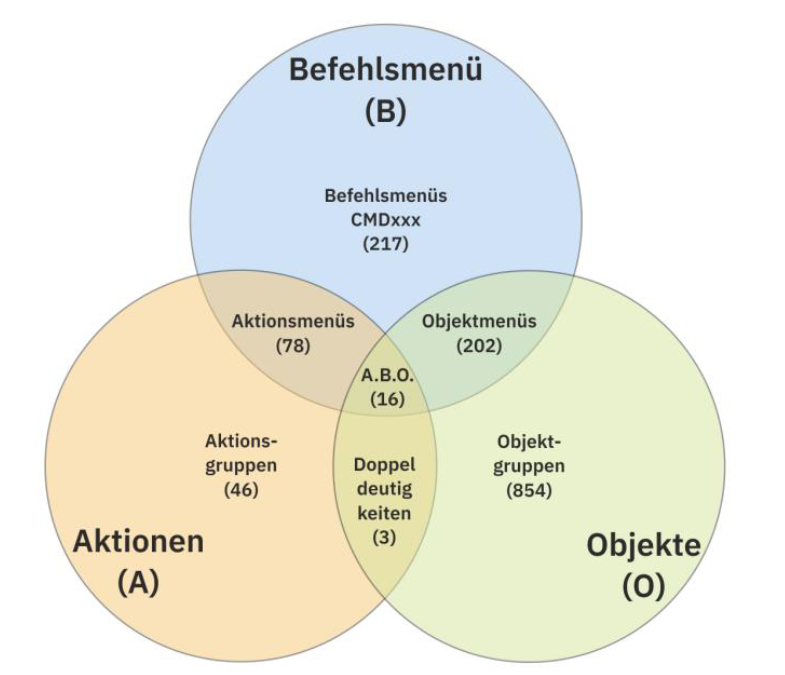
Abb. 3.3: Venn-Diagramm der
Mengenrelationen der Systembefehle
Ausschnitt der Befehlseinordnung für CMD
Besonders interessant wird es dann, wenn eine individuelle Analyse Abweichungen zum Standard ergibt, etwa weil auf Grund von Berechtigungen oder Änderungen deutlich weniger oder zusätzliche Befehle zu berücksichtigen sind. Diese werden ohne eine semantische Analyse oftmals nur dadurch entdeckt, dass Fehler auftreten – dann erinnert sich jemand, dass da noch ein paar hässliche Details gelten, die für die neu installierte Anwendung nicht funktionieren können, etwa weil Parameter fest belegt werden.
1) Reine Befehlsmenü-Gruppen (217)
B \ (A Ս O)
Die Menge der Befehlsgruppen für die keine direkte Übereinstimmung in den Befehlsnamen gefunden werden konnte (z.B. CMDRPG). Diese Menüs lassen sich weder einer Aktion, noch einem Objekt zuordnen. Diese Menge ist weiter interessant, da dort semantische Gruppierungen unabhängig vom Befehlsnamen zu finden sind und erfordern eine andere Art der Analyse als die einfache Zerlegung in Namenskomponenten.
2) Menge der Aktionsgruppen ( 46)
A \ (O Ս B)
Diese Menge enthält alle Namenskomponenten der Befehle, die eine Aktion darstellen (z.B. STR, CHG).
3) Menge der Objektgruppen (854)
O \ (A Ս B)
Diese Menge enthält alle Namenskomponenten der Befehle, die eine Objektrelation darstellen (z.B. OBJD, JOB).
4) Reine Aktionsmenüs (78)
(B ∩ A) \ O
Die Menge der Befehlsgruppen an Befehlsmenüs, die eindeutig einer Aktion zugeordnet werden können (z.B. CMDCHG).
5) Reine Objektmenüs (202)
(B ∩ O) \ A
Die Menge der Befehlsgruppen an Befehlsmenüs (s. Tab. 3.7), die eindeutig einer Objektrelation zugeordnet werden können (z.B. CMDJOB).
6) Doppeldeutig ohne Befehlsmenü (3)
(A ∩ O) \ B
Die Menge der Befehlsgruppen, welche Doppeldeutigkeiten zwischen Aktionen und Objekten aufweisen (z.B. LDIF). In diesem Fall liefert die Analyse der Namensbestandteile keine sinnvolle semantische Gruppierung (s. Tab. 3.8).
7) Doppeldeutig mit Befehlsmenü (16)
A ∩ B ∩ O
Die Untermenge der Doppeldeutigkeiten (s. Tab. 3.5) für die zudem Menüs existieren (z.B. QRY). Auch in diesem Fall liefert die Analyse der Namensbestandteile keine sinnvolle semantische Gruppierung.
Die beiden Mengen der Doppeldeutigkeiten sind entgegen der Erwartungen nicht leer.
Liste der A.B.O (16)
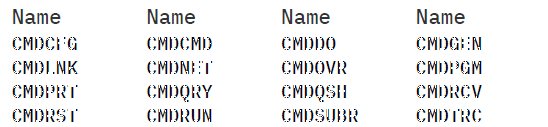
Tab. 3.5
Liste der Aktionsmenüs (78)
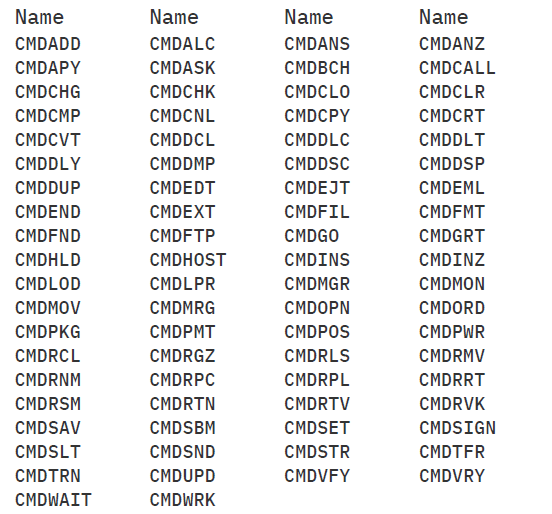
Tab. 3.6
Liste der Objektmenüs (202)
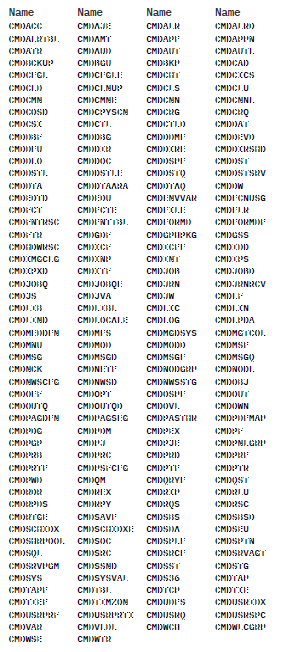
Tab. 3.7
Liste der Doppeldeutigkeiten (3)

Tab. 3.8
Die Doppeldeutigkeiten wollen wir zum Verständnis genauer aufschlüsseln, denn hinter jedem Element im Venn-Diagramm stecken am Ende Befehle aus dem System (ohne hier individuelle Anpassungen von Befehlen zu betrachten):
Liste der Befehle in Gruppe LDIF (#)

Tab. 3.9
Liste der Befehle in Gruppe PING (#)
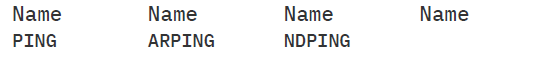
Tab. 3.10
Liste der Befehle in Gruppe SELECT (#)

Tab. 3.11
Es bedarf weiterer Informationen, um mögliche Doppeldeutigkeiten aufzulösen oder explizit abzubilden. Die extrahierten Konzepte der Aktionen, Objekte und Befehlsmenüs und ihrer Zusammenhänge werden als Konzepte in das Schema der IBM i Ontologie integriert.
Mit der vorgenommenen Analyse der Befehlsnamen kann die Ontologie weitgehend modelliert werden und ist für den gegebenen Kontext ausreichend.
Weitere Analysen wie z.B. die Untersuchung der Beschreibungen oder der Parameter von Befehlen ergänzen die Ontologie für Befehle, um mehr verlässliches Wissen für Abfragen bereitzustellen, wenn möglich auch so, dass es in anderen Sprachen analog abgeleitet werden kann.
Zugleich wird deutlich, dass eine Analyse von individuellen oder spezifischen Befehlen von entsprechenden Standards profitiert oder bei Abweichungen Fachwissen erforderlich wird, um die Ontologie entsprechend ergänzen zu können oder eine Anpassung vorzunehmen, um die eigenen Objekte sinnvoll in standardisierten Auswertungen berücksichtigen zu können, etwa wenn muttersprachliche Befehle (ANZBLD – ‘Anzeigen Bilder‘) anstelle von Standards (DSPIMG) genutzt werden.
Zugleich soll die Nutzung der Abfragen so weit wie möglich den umgangssprachlichen Zugang ermöglichen, also ‘Befehl‘ für die Identifizierung von ‘Command‘ oder ‘CMD‘ einsetzen zu können.
Fazit
Im Gegensatz zu einer SQL-Abfrage, in der die Daten im Detail bekannt sein müssen, also wie die Spezifikation der Datentypen und Werte aussieht und wo diese abzugreifen wären, wird dies durch die Ontologie semantisch verständlich und durch den Semantic Data Store visuell dargestellt.
Damit erhalten die Studierenden das Fachwissen, welches wir uns in 30 Jahren antrainiert haben, deutlich besser eingeordnet und strukturierter aufbereitet – ohne langwierige manuelle Suche in historischen Unterlagen.
Zugleich können einzelne Agenten zur Beschaffung der Daten lizensiert werden, so dass eine flexible Analyse und Erweiterung für individuelle Systeme erfolgen kann.
Ausblick
Im 4. Teil wird schrittweise die Ontologie konstruiert und zusammengefügt. Abschließend zeigt der 5. Teil die Vorteile des implementierten Vorgehens.
In Teil 5 zeigen wir dann, wie die Befehlsgruppen (s. Abb. 3.3) einfach (!) abgefragt und detaillierter betrachtet werden können, weil mit der Zuordnung über die Ontologie, die semantische Information dafür sorgt, dass der Einzelne gar nicht mehr wissen muss, wie die interne Analyse die Abfrage gestaltet.
Artikel dieser Serie:
1. Hilfe für IBM i Befehle
2. Grundlagen zu semantischen Auswertungen
• Ontologien (OWL)
• Resource Description Framework (RDF)
• Triple Data – Abfragen (SPARQL)
3. Analyse von IBM i Befehlen
• N-Gram Analyse von Befehlen
• Klassifizierung, Gruppen von Befehlen
4. Semantische Analysen zu IBM i Befehlen
• Modellierung einer Ontologie
• Abfragen erstellen
5. Semantic Data Store (SDS)
• Individuelle Auswertungen
• Lösung von Aufgaben
Über die Autoren

Autor Manfred Sielhorst
Manfred Sielhorst
Geschäftsführer der Sielhorst iT Beratung UG und Lehrbeauftragter der Hochschule Darmstadt im Fachbereich Informatik.

Autor Benjamin Walter
Benjamin Walter
Dualer Masterstudent an der Hochschule Darmstadt und seit 2013 bei der managetopia GmbH, Aschaffenburg.
Literatur
https://www.ibm.com/support/know ledgecenter/en/ssw_ibm_i_73/rbam6/
objec.htm
[4] M. Uschold and M. K. Aiai, “Towards a methodology for building ontologies”, 1995.
[5] A. Textor, Verknüpfung von Domänenwissen für ein Ontologie-basiertes IT-Management. PhD thesis, Kassel, 2018.
[13] P. Jackson, Introduction to Expert Systems. Boston, MA, USA: Addison-Wesley Longman Publishing Co., Inc., 3rd ed., 1998.
Ähnliche Artikel:
 POWER-Nachwuchs an der Hochschule Darmstadt Angeregt durch die Nachwuchs-Diskussion im NEWSolutions NEWSboard, erforscht diese Serie den aktuellen Status der IBM Academic Initiative. Dieser erste Bericht gewährt einen Einblick in die Tätigkeit des Dozenten Manfred Sielhorst…
POWER-Nachwuchs an der Hochschule Darmstadt Angeregt durch die Nachwuchs-Diskussion im NEWSolutions NEWSboard, erforscht diese Serie den aktuellen Status der IBM Academic Initiative. Dieser erste Bericht gewährt einen Einblick in die Tätigkeit des Dozenten Manfred Sielhorst…