von Chuck Stupka
|
Grundlagen zur Verwendung von Switched Disks
Die Unterstützung von Switched Disks zeigt einige grundlegende Charakteristika in V5R1, einschließlich der Unterstützung von IFS (integrated file system) und Netzwerk-Speichergeräten. Wenngleich diese beiden Features nur eine kleine Untermenge von iSeries-Objekten darstellen, unterstützen sie doch viele der am schnellsten wachsenden Applikationen auf der iSeries (z.B. Domino). Falls Sie diese Applikations- und Objekttypen nicht verwenden, machen Sie sich nichts daraus – bald werden weitere Objekte unterstützt werden. Falls Sie jetzt daran denken, Switched Disks zu implementieren, können Sie sich darauf verlassen, dass der Support, der zu Ihrer Umgebung passt, im Wachsen begriffen ist. Um Switched Disks zu benutzen, müssen Sie Ihre Systeme als Nodes (Knoten) in einem iSeries Cluster ausweisen und festlegen, zu welchen Nodes die Switched Disks gehören können. Sie müssen auch Produktions (primary)- und Sicherungssysteme (backup) bestimmen, um die jeweilige örtliche Festlegung der Switched Disks verwalten zu können. Weiter unten werden wir diese Themen ausführlicher behandeln. Switched Disks stellen einige Anforderungen an die Hardware. Sie müssen mit den Systemen über HSL (high-speed link) verbunden werden. Deshalb kommen nur die iSeries-Modelle 820, 830, 840 und 270 in Frage, da diese HSL unterstützen. Systeme, die über HSL verbunden sind, dürfen nicht weiter als 15 Meter voneinander entfernt sein. Sie müssen die Platteneinheiten in einem oder mehreren Türmen (Towers) unterbringen, die sich auf dem HSL zwischen den Systemen befinden, zu denen die Platten gehören können. Werden die Platten zwischen zwei Systemen umgeschaltet, so wird der gesamte Tower von einem System auf das andere geschaltet. Schließlich ist zu beachten, dass die Platten nur zwischen Systemen umgeschaltet werden können, die auf der HSL-Verbindung benachbart sind.
Wird auch als Beschreibung für das Bild verwendet
Die Einplanung von Switched Disks
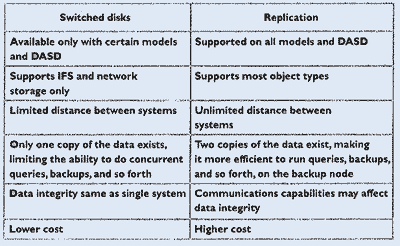
Ist ein Switched Disk-Cluster die richtige Wahl für Ihre Installation? Wahrscheinlich ja. Replikation könnte noch eine praktikable Option sein, oder Sie entscheiden sich, beides zu implementieren. Abbildung 1 zeigt einige Faktoren, die bedacht sein wollen, wenn Sie sich für eine Cluster-Implementierung entscheiden. Denken Sie daran, wenn Sie sich für Switched Disks entscheiden, sind Sie noch nicht geschützt vor Ausfällen auf Grund von Naturkatastrophen oder Sabotage-Akten. Für eine permanente Verfügbarkeit der Anlage ist jedoch die Implementierung von Switched Disks einfacher und kostengünstiger als die Replikation von Informationen zwischen Systemen. Wenn Sie sich entschieden haben, einen Switched Disk-Cluster zu verwenden, sollten Sie Ihre Hardware anhand der folgenden drei Schritte prüfen und bei Bedarf anpassen:
1. Entscheiden Sie, welche Systeme Teile des Clusters werden sollen und überzeugen Sie sich, dass diese in der Lage sind, Switched Disks zu unterstützen. Ist dies nicht der Fall, dann upgraden Sie die betroffenen Systeme, um eine entsprechende Unterstützung sicherzustellen.
2. Erstellen Sie einen Plan für die Konfiguration der HSL-Verbindung zwischen Ihren Systemen und stellen Sie deren Funktionsfähigkeit sicher, bevor Sie Ihre Switched Disks aktivieren.
3. Stellen Sie sicher, dass Ihre Plattengeräte und -türme eine Implementierung mit Switched Disks auch unterstützen. Erlaubt Ihre Plattenkonfiguration ein Umschalten zwischen Systemen nicht, sollten Sie Ihre Plattengeräte upgraden.
Switch Disk Abbildung 2
Wenn Sie diesen einfachen Schritten folgen, werden Ihre Systeme und Platten in der Lage sein, Switched Disks zu unterstützen, sobald Sie sich für ihre Implementierung entschieden haben. Jetzt können Sie damit beginnen, Ihre Switched Disk-Umgebung zu planen. Während der Planungsphase sollten Sie festlegen
- welche Objekte auf den Switched Disks gespeichert werden sollen
- Größe und Zuwachsrate jedes Objektes (da Sie Switched Disks als Hilfsspeicher-Pool – ASP = auxiliary storage pool – implementieren, müssen Sie die erforderliche Plattenkapazität für Ihre Objekte bereitstellen. Ein voller ASP würde bewirken, dass jede Applikation, die Informationen an ihn schickt, auf Fehler läuft.
- das die Switched Disks nutzende System, das Eigentümer (primary owner) der Geräte ist und das System, das als Sicherungssystem fungieren soll
- die Applikationen, die die Daten auf den Switched Disks benutzen werden.
Mit diesen Angaben können Sie Ihre Umgebung soweit definieren, dass sich die Applikationen und Platten koordiniert von System zu System bewegen können.
Switch Disk Abbildung 3
Implementierung eines 2-Nodes-Clusters
Nach Beendigung Ihrer Planung können Sie Ihren Cluster unter Verwendung von Switched Disks implementieren. Betrachten wir die Stufen der Implementierung eines 2-Nodes-Clusters mit einem Tower Switched Disks. Zuerst erzeugen Sie einen Cluster mit zwei Systemen als Nodes im Cluster. Anschließend folgen Sie bitte den im Folgenden beschriebenen drei Stufen, um die Nodes im Cluster zu definieren:
1) Vergewissern Sie sich, dass der Job INETD im Hintergrund auf Ihren beiden Nodes läuft:
- STRTCPSVR *INETD
2) Konfigurieren Sie redundante TCP/IP-Verbindungen zwischen den Nodes, um Cluster-Probleme zu verhindern, die durch Fehler einer Einzelverbindung verursacht werden.
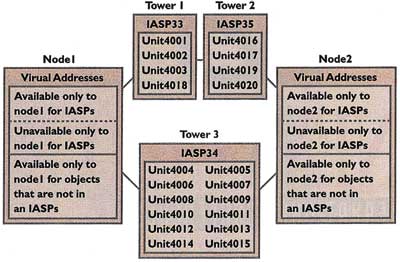
3) Lassen Sie die Create Cluster-Operation ablaufen. Die zwei Systeme, die Sie als Produktions- und als Sicherungssystem in der Planungsphase auswählen, sollten die Cluster-Nodes sein und die IP-Adressen aufführen, die Sie zu einem früheren Zeitpunkt festgelegt haben. An dieser Stelle können Sie den neuen Support in V5R1 nutzen, um die Platten als Geräte festzulegen, die zwischen zwei Nodes im Cluster umgeschaltet werden können. Um Switched Disks zu verwenden, muss der Cluster eine Device-Domain verwenden, eine neue Funktion in V5R1. Einfach ausgedrückt, kann man unter der Device-Domain die Liste der Nodes in einem Cluster verstehen, die Eigentümer des Towers sein kann, in dem sich die Switched Disks befinden. Die Nodes müssen in die Device Domain eingetragen werden, um Eindeutigkeit sicherzustellen für ASP-Nummer, Nummer des Plattenlaufwerks und virtuelle Adresse.
ASP (auxiliary storage pool)-Nummer
Ein unabhängiger ASP enthält die Switched Disks. Um Eigentümer der Platten zu werden, muss ein Node erst Eigentümer des unabhängigen ASPs sein. Aus diesem Grund muss jeder unabhängige ASP, der Eigentum einer der Nodes sein kann, eine eindeutige identische Nummer in beiden Nodes besitzen.
Plattenlaufwerksnummer
Ähnlich den ASPs, die von einem System zum nächsten wechseln können, müssen die Plattenlaufwerke, die zwischen Systemen wechseln, eine eindeutige Nummer in den Systemen haben.
Virtuelle Adresse
Die iSeries weist virtuelle Adressen innerhalb eines Systems zu und kennt die Adressen, die von einem anderen System verwendet werden, nicht. Hinzu kommt, dass die Definition der Adresse (die Abbildung der Adressen auf Objekte) innerhalb eines jeden Systems eindeutig ist und so das Umschalten von Platten zwischen den Systemen verhindert. Wenn Sie jedoch eine Device Domain verwenden, können Sie einen Teil des Adressraumes zwischen den Nodes segmentieren – ein Node kann Adressen innerhalb eines bestimmten Bereichs zuweisen und der andere Node kann sie nicht benutzen. Ähnlich können Sie eine andere Adress-Menge dem zweiten Node zuweisen und sie für den ersten nicht verfügbar machen. Abbildung 2 zeigt diese Device Domain-Features.
Switch Disk Abbildung 4
Switched Disks arbeiten lassen
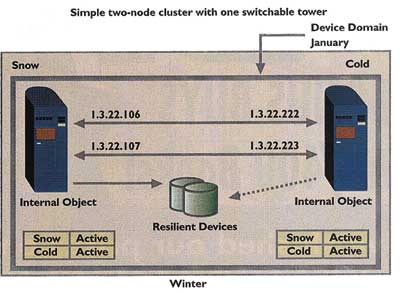
Nachdem Sie nun gesehen haben, wie die iSeries angepasst werden muss, um Switched Disks zu benutzen, betrachten wir eine Modell-Umgebung, die Switched Disks arbeiten lässt. In unserer Umgebung haben wir zwei Nodes im Cluster, beide in derselben Device Domain, und einen unabhängigen ASP in einem Tower zwischen den beiden Systemen. Zusätzlich existieren folgende Verhältnisse (siehe Abbildung 3):
- Der Name des Clusters ist „Winter„
- Die Namen der Nodes im Cluster sind „Snow„ und „Cold„
- Die Device Domain, die die beiden Nodes Snow und Cold enthält, ist „January„
- Die umschaltbaren Geräte sind Plattenlaufwerke in einem Tower, der über HSL mit den beiden Nodes in der Device Domain verbunden ist.
Wir haben nun die Switched Disk-Hardware und die Device Domain definiert. Um jedoch den ASP als ein Set von Platten zu definieren, das zwischen den beiden Nodes in der Device Domain hin- und hergeschaltet werden kann, ist es erforderlich, mehr OS/400 Cluster-Support in Anspruch zu nehmen.
Erzeugung einer Geräte-Cluster Resource Group (CRG)
Sie verwenden CRGs, um sog. Resiliency (eine Messgröße für Robustheit) von Daten, Applikationen und Geräten (neu in V5R1) festzulegen. Um den Ort unserer Switched Devices zu definieren und zu überwachen, erzeugen wir einen Geräte-CRG, der einige Schlüsselelemente enthält:
- Bestimmung des Primary und Backup Nodes. Dieses CRG-Element zeigt nur an, welcher Node anfänglich Eigentümer der Plattenlaufwerke ist, und welcher Node Eigentümer der Platten wird, wenn der Primary Node ausfallen sollte.
- Geräte, die vom Produktiv- auf das Sicherungssystem wechseln können. Dieses Element identifiziert den ASP, der zwischen den Systemen hin- und hergeschaltet werden soll. In unserem Beispiel haben wir nur einen unabhängigen ASP, es sind jedoch auch mehrere möglich. Wir haben auch nur einen Tower, möglich sind maximal drei (abhängig von der Systemhardware). Ein unabhängiger ASP kann mehrere Tower umspannen. Wenn der Primary Node ausfällt, schalten alle Tower, die Switched Disks enthalten, vom Primary Node zum Backup Node.
- Kennzeichenänderung. Diese Einstellung automatisiert Änderungen bei Geräten, wann immer Platten von einem Node zu einem anderen geschaltet werden. Die Notwendigkeit zum Umschalten von Geräten kann auftreten, wenn das Produktionssystem ausfällt oder eine Verwaltungsanforderung die Plattenlaufwerke umschaltet. In beiden Fällen wird die Änderung ausgeführt gemäß der von Ihnen eingestellten Kennzeichenänderung. Keine anderen Clusterereignisse bewirken entsprechende Änderungen der Komponenten.
- Ein CRG Exit-Programm. Dieses vom Benutzer geschriebene Programm wird immer dann aufgerufen, wenn irgendeine Cluster-Aktion passiert. Das Programm kann Konditionen verwalten, die OS/400 nicht automatisch behandelt. Z. B. gibt es verschiedene Cluster-Ereignisse, bei denen eine Veränderung des Status „ein„ oder „aus„ wünschenswert wäre, aber OS/400 führt diese Veränderung nicht aus. Hier kann ein vom Anwender geschriebenes Programm einspringen und die Funktionsänderung ausführen.
Bei der Erzeugung unserer Geräte-CRGs haben wir die Resiliency für unsere Platten definiert. Um diese zu aktivieren, benutzen wir eine Cluster-Operation, um die CRG zu starten. Da OS/400 nicht automatisch Geräteänderungen während einer Startoperation durchführen wird, sollte Ihr Exit-Programm diese Funktion ausführen. In unserem Beispiel wird ResDev die Geräte-CRG sein.
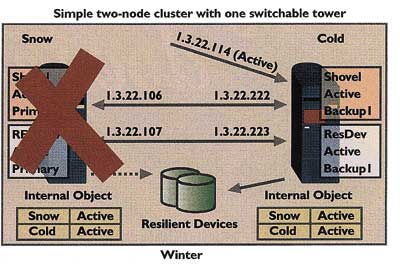
Switch Disk Abbildung 5
Erzeugung einer Applikations-CRG
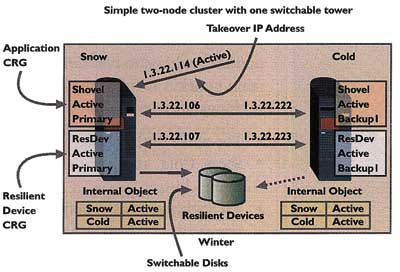
Eine Applikations-CRG führt viele identische Funktionen aus wie auch eine Geräte-CRG, wird aber auch benutzt, um die Primary Location für die Applikationsanwender zur Verfügung zu stellen. Obwohl die resiliente Geräte-CRG die Platten versorgt, um zwischen den Nodes umgeschaltet zu werden, stellt die Applikations-CRG eine IP-Adresse bereit, die zwischen einem Primary- und einem Backup-Node umgeschaltet werden kann. Auf diese Weise greifen unsere Anwender auf das System zu über eine IP-Adresse, die von einer CRG verwaltet wird, und sie greifen auf Geräte zu, die von einer CRG gesteuert werden. In unserem Beispiel heißt die Applikations-CRG Shovel (siehe Abbildung 4). Wie Sie in der Abbildung sehen können, wurde die IP-Adresse gestartet und der umschaltbare Tower ist gerade im Primary bzw. Produktions-System aktiviert. Sollte es zu einer Störung kommen, werden sowohl der Tower als auch die IP-Adresse auf das Backup bzw. Sicherungssystem geschaltet (siehe Abbildung 5). Der OS/400 Cluster-Support und die benutzergeschriebenen, der CRG angeschlossenen Exit-Programme verschieben die Applikation und die Switched Disks. Zusätzlich kann OS/400 Cluster-Support automatisch Veränderungen auf den umgeschalteten Geräten im Sicherungssystem vornehmen. Wenn Sie das ursprüngliche Primary System auf Service zurücksetzen, indem Sie die Applikation und die Switched Disks auf das ursprüngliche Primary System zurücksetzen, so erfordert dies eine administrative Maßnahme. Außerdem können die Platten so lange nicht verschoben werden, solange noch ein Anwender auf Daten zugreift, die sich auf den Switched Disks befinden. Aus diesem Grund sollten alle jene, die auf Daten auf den Platten zugreifen, ihre Jobs beenden, bevor der Versuch unternommen wird, die Geräte auf das ursprüngliche Primary System zurückzuschalten.
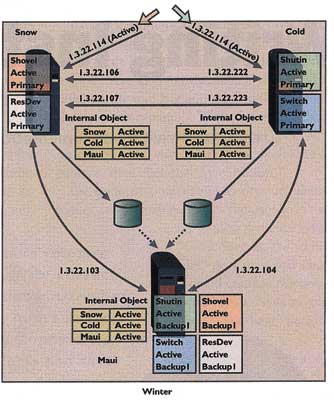
Switch Disk Abbildung 6
Ein Node für die allgemeine Sicherung
Abbildung 6 zeigt eine komplexere aber übliche Umgebung. Ein System wird verwendet als Sicherungssystem für Switched Disks, die an zwei verschiedene Primary Nodes angeschlossen sind. Folgende Eigenschaften finden sich in diesem Cluster:
- Der Name des Clusters ist „Winter„.
- Die Nodes im Cluster heißen „Snow„, „Cold„ und „Maui„
- Eine Applikations-CRG mit Namen „Shovel„ repräsentiert und verwaltet Anwender, die auf Informationen auf den Switched Disks zugreifen, die wiederum repräsentiert und verwaltet werden durch den resilient Geräte-CRG mit dem Namen ResDev.
- Die Recovery-Domains sowohl für ResDev als auch für Shovel haben als Primary Node „Snow„ und als Backup Node „Maui„.
- Eine Applikations-CRG mit Namen „Shutin„ repräsentiert und verwaltet Anwender, die auf Informationen auf den Switched Disks zugreifen, die wiederum repräsentiert und verwaltet werden durch den resilient Geräte-CRG mit dem Namen „Switch„.
- Die Recovery-Domains sowohl für „Switch„ als auch für „Shutin„ haben „Cold„ als Primary Node und „Maui„ als Backup Node.
Berücksichtigen Sie bitte, dass die Device Domains nicht angezeigt werden. Seit ein Node (Maui) Eigentümer beider Sets von Switched Disks sein kann, müssen die ASP-Nummern, die Nummern der Platteneinheiten und die virtuellen Adressen eindeutig, also gleich sein über alle drei Nodes. Daraus ergibt sich, dass sich alle drei Nodes in derselben Device Domain befinden müssen. Wenn ein oder beide Primary Nodes ausfallen, werden Platten und Anwender automatisch auf „Maui„ umgeschaltet und können dort die Verarbeitung fortsetzen – und so wird jeglicher Konflikt zwischen ASP-Nummern, Nummern der Platteneinheiten oder virtuellen Adressen vermieden.
LPAR-Erweiterungen für Switched Disk-Implementierungen
Die Verwendung von Switched Disks in einem LPAR-Cluster bringt zum angebotenen Support verschiedene Erweiterungen mit sich:
- Anstatt einen ganzen Tower umzuschalten, können Sie dies für einzelne Geräte tun.
- Sie können Geräte auf beliebige LPAR-Partitionen umschalten. Wenn Sie Ihr System z. B. in sechs Partitionen aufgeteilt haben, können Sie Platteneinheiten unter einem E/A-Prozessor (IOP) von der zweiten Partition auf eine beliebige der übrigen fünf umschalten.
Die Fähigkeit, auf IOP-Level Platten umzuschalten, bietet mehr Flexibilität und niedrigere Kosten für kleine Switched Disk-Umgebungen. Seit eine LPAR-Implementierung mehr als eine Sicherung für ein Set Switched Disks anbieten kann, erhalten Sie für bestimmte Umstände (z. B. Wartung oder Ausfall der Partition) zusätzliche Verfügbarkeit. LPAR ist jedoch noch eine einzelne iSeries-Maschine, so dass viele Arten von Störungen (z. B. versehentliche Unterbrechung der Stromversorgung) zur Konsequenz haben, dass alle Switched Disks nicht mehr verfügbar sind. Mit anderen Worten: eine einzelne LPAR-Maschine ist keine dauerhafte Verfügbarkeits-Lösung.
Ein großer Schritt nach vorne
Die Einführung von Switched Disks für die iSeries ist ein echter technologischer Fortschritt, der die Akzeptanz des iSeries Cluster-Supports erhöhen und vielen Kunden dauerhafte Verfügbarkeit sichern wird. V5R1 unterstützt nur eine begrenzte Anzahl von Objekten, die Zukunft wird jedoch eine Erweiterung auf eine ganze Reihe weiterer OS/400-Objekte bringen, die Applikationen gewöhnlich nutzen. Da der Support in diesem Bereich wächst, können Sie Switched Disks bedenkenlos implementieren, um Ihre Umgebung zu optimieren. Weitere Informationen zur Gestaltung Ihres Switched Disk-Systems finden Sie unter der iSeries Hochverfügbarkeits-Website www.iseries.ibm.com/ha und unter dem iSeries-Informationszentrum www.iseries.ibm.com .
|
Übersetzt und für den deutschsprachigen Markt überarbeitet von Winfried Steiner
|
Ähnliche Artikel:


