© tom-kirchgaessner.de und Jason Leung
von Manfred Sielhorst, Benjamin Walter
Teil 4 — Semantische Analysen
4.1 Schrittweise Modellierung der Ontologie mit Wissensdomänen
Zur Modellierung des Wissens in einer Ontologie existieren drei Domänen in denen die bottom-up Methodik angewandt wird.
1) Basiswissen
2) Problemwissen
3) Lösungswissen
Jede Domäne wird für sich betrachtet und repräsentiert einen Teilbereich der gegebenen Aufgabenstellung. Als letzter Schritt wird die Domäne in das Gesamtkonzept der Ontologien zum IBM i Umfeld integriert.
4.1.1 Basiswissen modellieren
Aufbauend auf den grundlegenden Strukturen der IBM i Systeme wird das Wissen aus Teil 2 genutzt, um das Basiswissen in der Ontologie zu modellieren.
Abbildung 4.1 zeigt die drei Grundkonzepte Bibliothek (Library), Objekt (Object) und Befehl (Command), sowie die Beziehungen untereinander.
Eine Bibliothek ist ebenso ein spezielles Objekt wie ein Befehl. Zudem ist ein Objekt ein Teil einer Bibliothek mit der memberOf Beziehung.
Die drei Klassen verfügen über weitere Eigenschaften zur Benennung (name) und Beschreibung (description). Diese Felder werden von Objekt zu Bibliothek und Befehl vererbt (SubClassOf).

Abbildung 4.1: Modellierung des Basiswissens (Eigene Darstellung mit VOWL [14])
Damit lassen sich die zugrunde liegenden Objekte der IBM i Infrastruktur explizit in einer Ontologie abbilden.
4.1.2 Problemwissen modellieren
Als Problemwissen ist das Wissen eingeordnet, welches zur Beschreibung von Fragestellungen dient. Dieses Wissen basiert auf der Ist-Analyse aus Teil 3 dieser Reihe. Abbildung 4.2 zeigt den resultierenden Ausschnitt der Ontologie. Ziel ist es, die Gruppierung der Befehle zu modellieren. Aus Teil 3 ist zudem bekannt, dass es Objektgruppen (ObjectGroup) und Aktionsgruppen (ActionGroup) gibt.
Eine Objektgruppe hat einen direkten Bezug zu Objekten mit der relatesTo Beziehung. Die undefinierte Gruppe (UndefinedGroup) dient als expliziter Platzhalter für die Doppeldeutigkeiten und generell den Befehlen, welche noch nicht zugeordnet wurden. Mit der OWL2 können detaillierte Äquivalenzklassen konstruiert werden, welche aussagen, dass ein Befehl der keiner anderen Gruppe angehört, automatisch Teil der undefinierten Gruppe ist.
Aus diesem Sachverhalt kann generalisiert werden, dass es eine allgemeine Befehlsgruppe mit zugehörigen Eigenschaften gibt.
Wie aus dem Kontext des Basiswissens hervorgeht (s. Abschnitt 4.1.1) ist jeweils ein Name und eine Beschreibung sinnvoll, um weitere Metainformationen zu erfassen. Ein Bezeichner (specifier) dient der Identifikation mit einem definierten Begriff (Bsp. WRK). Diese können bei Bedarf in unterschiedlichen Versionen und Sprachen ergänzt und genutzt werden.
4.1.3 Lösungswissen modellieren
Als Lösungswissen wird das Wissen bezeichnet, welches zur Lösung beiträgt. Konkret in der Ontologie ist es das Wissen, welches benötigt wird, um das Problemwissen aus Abschnitt 4.1.2 mit den Befehlsnamen zu verknüpfen.
Abbildung 4.3 zeigt die bereits bekannte Beziehung zwischen Befehl und Befehlsgruppe partOf. Darauf aufbauend wird der Befehlsname (CommandName) als eigenes Konzept abgebildet. Befehlsnamen sind damit nicht länger reine Daten, sondern bezeichnen auch fachliche Relationen.
Der Befehlsname wird dann in Teile (CmdNamePart) zerlegt. Diesen Teilen wird über die Eigenschaft value der zugehörige Wert zugeordnet. Weiterhin wird analog zur Analyse aus Teil 3 den Namensteilen eine Bedeutung im Sinne von Aktionsbeziehung (ActionPart) oder Objektbeziehung (ObjectPart) zugeordnet.
Die jeweilige Zuordnung der Namensteile zu einer Befehlsgruppe erfolgt mit der Beziehung makesPartOf.
4.2 Zusammenfassung der Modelle
Aus den Abschnitten 4.1.1, 4.1.2 und 4.1.3 ist in mehreren Schritten ein für die jeweiligen Anforderungen spezifischer Teil der Ontologie entstanden. Abbildung 4.4 zeigt die vollständige entstandene Ontologie. In der Ontologie findet sich das gesammelte Wissen aus den vorherigen Analysen aus Teil 3 unter Berücksichtigung der Anforderungen an die IBM i Infrastruktur aus Teil 2 und der angestrebten Zielsetzung, der Einordnung der Befehle in Befehlsgruppen, basierend auf den Befehlsnamen.
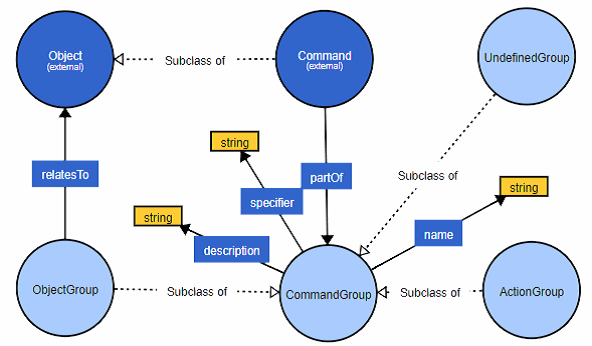
Abbildung 4.2. Modellierung des Problemwissens (Eigene Darstellung mit VOWL [14])
4.3 Vorteile der semantischen Suche
Die semantische Suche hat für die Benutzer folgende Vorteile:
- Fragen einfacher und präziser stellen
- Wissen explorativ nutzen
- Wissen kann flexibel hinzugefügt werden
- Modelliertes Wissen in Form der Ontologie kann genutzt werden, um gezielte Anfragen zu stellen
Mit dem klassischen Ansatz (OUTFILE) ist es möglich, eine SQL-Datenbank zu Befehlen in einer Bibliothek ‚LIB‘ aufzubauen und diese mit dem neu gewonnenen semantischen Wissen zu verknüpfen.
4.3.1 Abfrage mit SQL erstellen
Um eine Suche nach dem Kontext ‚Befehl‘ zu ermöglichen, sind mindestens die folgenden zwei sprachabhängigen SQL-Statements notwendig.
Die folgende SQL Abfrage sucht im Befehlsnamen an beliebiger Stelle nach der Zeichenfolge ‚CMD‚:
SELECT ODOBNM, ODOBTX FROM LIB.CMDOUT WHERE ODOBNM LIKE ’%CMD%’
Als Ergebnis liefert die Abfrage die Tabelle 4.1 mit 17 Befehlen und zusätzlich den folgenden Eintrag:
ANZCMDPFR -- Analyze Command Performance
Zusätzlich kann mit der folgenden SQL Abfrage nach der sprachabhängigen Zeichenfolge ‚Befehl‘ in der Beschreibung der Befehle gesucht werden:
SELECT ODOBNM, ODOBTX FROM LIB.CMDOUT WHERE ODOBTX LIKE ’%Befehl%’
Als Ergebnis liefert diese Abfrage ebenfalls die gleiche Tabelle 4.1 mit 17 Befehlen und darüber hinaus den folgenden Eintrag:
AREXEC -- Fernen Befehl ausführen
Die gewünschte Lösung hat damit eine kombinierte Länge von 19 Einträgen.
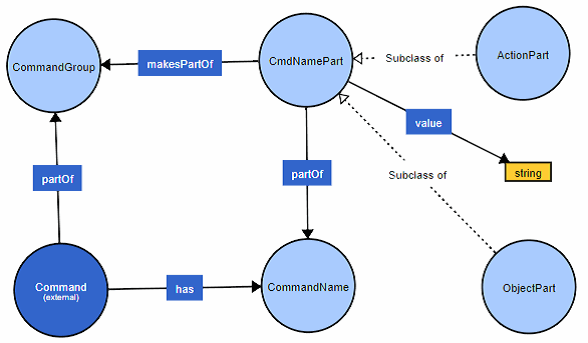
Abbildung 4.3. Modellierung des Lösungswissens (Eigene Darstellung mit VOWL [14])
4.3.2 Abfrage mit SPARQL erstellen
Dem gegenüber kann eine Anfrage im SDS durch SPARQL [7] gestellt werden, welche direkt die gewünschte vollständige Liste liefert.
Die folgende SPARQL Abfrage basiert auf der Ontologie aus Abbildung 4.4 und zeigt wie einfach dies formuliert werden kann, wenn die visuelle Darstellung der Ontologie (VOWL) [14] genutzt wird.
Kommentarzeilen beginnen mit einem ‚#‘:
Listing 1. SPARQL Abfrage
SELECT ?cmdName {
# Beziehe Objekte vom Typ Befehle ein
?cmd a ibmi:Command.
# Hole den Namen als Variable
?cmd ibmi:name ?cmdName.
# Suche nach Objektgruppen
?group a :ObjectGroup.
# Wähle die Gruppe,
# die sich auf Befehle bezieht
?group :relatesTo ibmi:Command.
# Wähle Befehle, die Teil der Gruppe sind
?cmd :partOf ?group.
}
Es wird mit SPARQL keine Textsuche wie in den vorherigen SQL Anfragen genutzt, sondern explizit semantisch auf den Sachverhalt eingegrenzt. Zunächst erfolgt mit den Variablen ?cmd und ?cmdName die Einschränkung der gewünschten Lösung auf Befehle und deren Namen. Mit der Variablen ?group wird der Kontext der Suche auf eine Objektbeziehung zu den Befehlen angegeben.
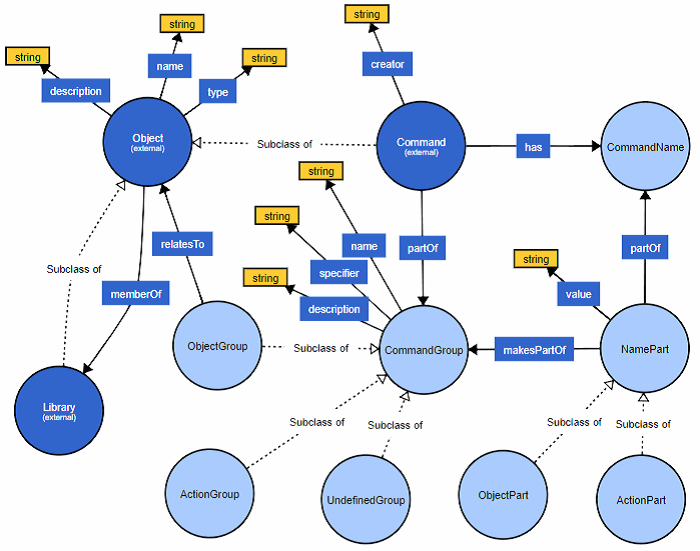
Abbildung 4.4. Ontologie zur Wissensrepräsentation (Eigene Darstellung mit VOWL [14])
Durch diese semantische Formulierung der Anfrage in SPARQL wird das vollständige Ergebnis zurückgegeben, also die Befehle aus Tabelle 4.1 sowie ANZCMDPFR und AREXEC.
Da ist mit dem SQL-Zugriff auf ein OUTFILE schon etwas mehr Aufwand erforderlich, um die Liste in einem Schritt zu erhalten, speziell wenn dann mehrere Versionen von IBM i in mehreren Sprachen unterstützt werden müssten, würde die Lösung sukzessive deutlich komplexer, während in SPARQL einfach die zusätzlichen logischen Anforderungen als Tripel (subject, predicate, object) logisch ergänzt würden (mit ‚und‘, nicht‘, ‚oder‘), nachdem die Ontologie entsprechende Ergänzungen erhalten hat.
Tabelle 4.1: Schnittmenge der SQL-Abfragen

Aus Abschnitt 4.2 ist eine Ontologie entstanden mit der sowohl das Aufgabenfeld der Befehlsgruppierung als auch die Einordnung von Befehlen in diese Gruppen vorgenommen wird. Der Vergleich aus Abschnitt 4.3 zwischen dem klassischen Ansatz mit SQL gegenüber der semantisch unterstützten Suche mit SPARQL hat den entstandenen Mehrwert an einem Praxisbeispiel gezeigt.
Zusammen genommen hat die angewendete Methodik zu einem mehr als zufrieden stellenden Ergebnis geführt und weiterhin gezeigt, dass Verbesserungspotential für komplexe Analyse vorhanden ist und mit SDS auch genutzt werden kann.
Dieses Potential resultiert aus der Einfachheit der Analyse der Befehlsnamen und zeigt zugleich auch die Mächtigkeit einer solchen Analyse. Durch zusätzliche Datenquellen wie beispielsweise Objekt- oder Befehlsattribute, sowie einer detaillierten Analyse der Inhalte der Systemmenüs können die angesprochenen Doppeldeutigkeiten bestimmt werden.
Auch können weitere Gruppen gebildet werden, welche sich nicht nur auf Aktionen oder Objektrelationen beschränken, sondern auch inhaltlicher Natur sind (Ausgaben zu DSPCMD in Abb. 1.7 in Teil 1). Mit dem gezeigten exemplarischen Ansatz kann somit der Grundstein für Unterstützungen der Anwender der IBM i Infrastruktur gelegt werden.
Die Verwendung dieser Technologie ermöglicht zum Beispiel Firmen, die IBM i einsetzen, neue sowie erfahrene Mitarbeiter durch eine semantische Analyse schneller in neue Teilbereiche der Infrastruktur einzuarbeiten.
Dabei bleibt die Technologie für neues Wissen offen und kann jederzeit erweitert oder angepasst werden und ist dadurch weit über die initiale Aufgabenstellung hinaus einsetzbar.
Dafür ist nicht wie im klassischen Ansatz ein Datenmodell zu erstellen, in dem viele Spalten nur spärlich und nachträglich zu besetzen sind. Die neuen Informationen werden als zusätzliche Knoten im Graphen angefügt und genutzt, wo diese sinnvoll sind und sollte über die Ontologie entsprechend beschrieben werden.
Mögliche Anwendungsszenarien umfassen die zusätzlichen Analysen von Nachrichten und Logs oder ganzer Anwendungen der IBM i Infrastruktur.
Artikel dieser Serie:
- Hilfe für IBM i Befehle
- Grundlagen zu semantischen Auswertungen Ontologien (OWL) Resource Description Framework (RDF) Triple Data – Abfragen (SPARQL)
- Analyse von IBM i Befehlen N-Gram Analyse von Befehlen Klassifizierung, Gruppen von Befehlen
- Semantische Analysen Modellierung einer Ontologie Abfragen erstellen
- Semantic Data Store (SDS) Individuelle Auswertungen Lösung von Aufgaben
Ausblick
Ziel ist die sukzessive modulare Erweiterung von IBM i Ontologien und die Erstellung von Lösungsszenarien mit Hilfe des semantischen Wissens.
Dies soll für Abfragen zu Standardumgebungen (reines Betriebssystem), für individuelle Umgebungen (Customized) und für ältere Versionen des Betriebssystems / der Anwendungen (Versionierung) angeboten werden.
In Teil 5 zeigen wir, wie die Befehlsgruppen abgefragt und detaillierter betrachtet werden können, weil mit der Zuordnung über die Ontologie, die semantische Information dafür sorgt, dass der Einzelne gar nicht mehr wissen muss, wie die interne Abfrage für die Analyse gestaltet wird.
Literatur
[9] A. Seaborne and S. Harris, “SPARQL 1.1 query language,” W3C recommendation, W3C, Mar. 2013. http://www.w3.org/TR/2013/REC-sparql11-query-20130321/.
[14] S. Negru, S. Lohmann, and F. Haag, “Vowl specification.” http://vowl.visualdataweb.org/v2/, Abgerufen am 2019-03-29.

Autor Manfred Sielhorst
Über die Autoren
Manfred Sielhorst
Geschäftsführer der Sielhorst iT Beratung UG und Lehrbeauftragter der Hochschule Darmstadt im Fachbereich Informatik.

Autor Benjamin Walter
Benjamin Walter
Dualer Masterstudent an der Hochschule Darmstadt und seit 2013 bei der managetopia GmbH, Aschaffenburg.