von Sabine Jordan

FlashCopy erzeugt eine Point-in-Time-Kopie
FlashCopy ist eine Funktion eines IBM Storage Systems. Es ermöglicht die Erstellung einer Zeitpunktkopie eines logischen Volumes. Dabei wird eine sogenannte FlashCopy Relationship zwischen dem Quell-Volume und dem Ziel-Volume erzeugt – die beiden Volumes bilden ein Flash- Copy Paar. Da ein IBM i System im Normalfall nicht auf einem einzigen logischen Volume liegt, ist es notwendig, dass für alle beteiligten Volumes die FlashCopy zum exakt gleichen Zeitpunkt erzeugt wird. Dazu werden sogenannte Consistency Groups verwendet – eine Zusammenfassung von zusammengehörenden Volumes. Wenn eine FlashCopy gestartet wird, so wird im ersten Schritt die entsprechende Relationship gebildet. Die Ziel-Volumes sollen dabei möglichst sofort für die Verwendung zur Verfügung stehen – und nicht erst, wenn eine entsprechend große Datenmenge tatsächlich physisch kopiert wurde. Dazu wird eine Bitmap verwendet, die definiert, auf welchem Volume (Quelle oder Ziel) sich die entsprechenden Daten tatsächlich befinden. Zum Kopierzeitpunkt liegen alle Speicherseiten auf dem Quellvolume. Sobald die Bitmap geschrieben wurde, kann sowohl der Zugriff auf die Quellals auch auf die Zielvolumes freigegeben werden.
Wird zu einem späteren Zeitpunkt eine Speicherseite auf dem Quellvolume geändert, so wird vor dieser Änderung der alte Zustand zuerst in das Zielvolume kopiert und die Bitmap entsprechend geändert.
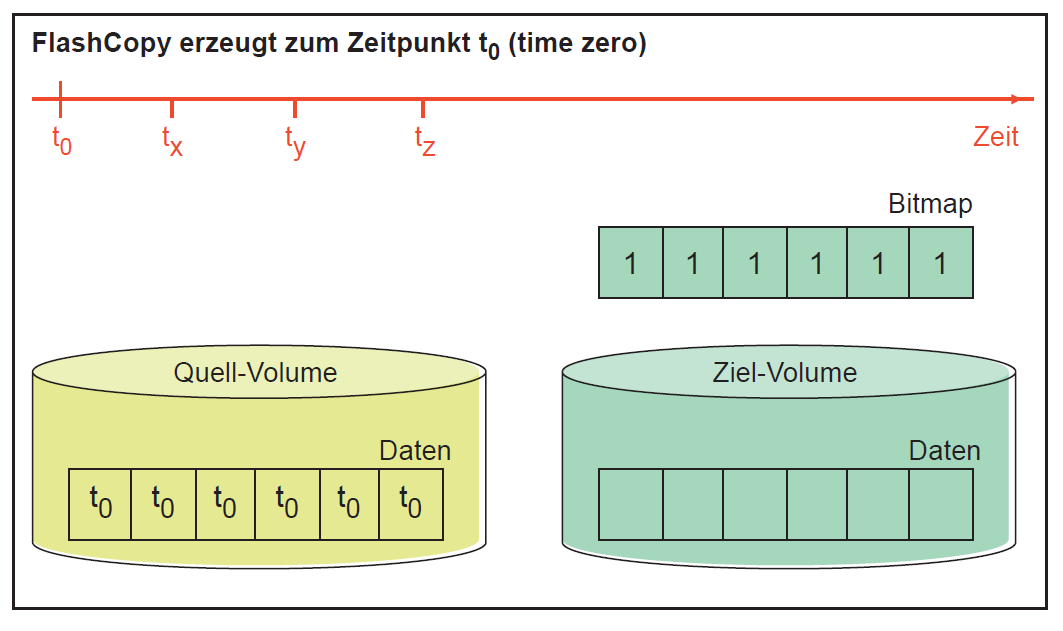
Auch Änderungen auf den Zielvolumes werden entsprechend behandelt – liegen die Speicherseiten bisher unverändert auf den Quellvolumes, so werden die gewünschten Änderungen auf das Zielvolume geschrieben und die Bitmap entsprechend verändert.
Dieser Vorgang wird komplett vom Storagesystem gesteuert – IBM i „sieht“ nur die entsprechenden Volumes und führt Schreib- und Leseoperationen ganz normal aus.
Es gibt eine Reihe von unterschiedlichen Möglichkeiten, eine Flash- Copy zu erzeugen. Wird eine „Full Copy“ ausgewählt, so werden zusätzlich zum oben beschriebenen Prozess alle Daten von den Quellvolumes zu den Zielvolumes kopiert, so dass am Ende des tatsächlichen physischen Kopiervorganges zwei eigenständige Kopien der Daten zu Verfügung stehen. Dieses Verfahren kann zum Beispiel verwendet werden, wenn Lasttests gefahren werden sollen, die nicht die Performance der normalen Anwendung beeinflussen sollen und deshalb auf separaten Volumes laufen.
Eine „space efficient“ FlashCopy verzichtet hingegen auf das vollständige Kopieren aller Daten. Lediglich Daten, die im Quell- oder im Zielvolume geändert werden, werden entsprechend kopiert – für alle anderen Daten erfolgt der Zugriff weiterhin über das Quellvolume. Dieses Verfahren spart entsprechend Platz im Storagesystem – und kann zum Beispiel verwendet werden, um aus der FlashCopy Datensicherungen zu fahren. Das Zielvolume kann hier nicht unabhängig vom Quellvolume existieren – es ist nur so lange nutzbar, wie die FlashCopy Relationship existiert.
Was passiert mit Daten im Hauptspeicher?
FlashCopy ist eine reine Funktion des Storage Systems – damit werden Daten, die sich im Hauptspeicher befinden, nicht mit kopiert – sondern lediglich die Daten, die sich bereits im Storage System befinden. Wird eine FlashCopy erzeugt, während die zugehörige IBM i LPAR heruntergefahren ist (oder der entsprechende iASP abgehängt ist), so wurden beim Herunterfahren alle Daten aus dem Hauptspeicher auf die Platte geschrieben – und damit sind auch alle Daten sauber in der FlashCopy enthalten.

Wird die FlashCopy hingegen auf einem laufenden System erzeugt, so stellt sich diese FlashCopy aus Sicht des Betriebssystems dar wie ein System nach einem abnormalen Systemende. Während des folgenden abnormalen IPLs wird eine Datenbankrecovery gestartet. Dabei wird geprüft, welche Dateien zum Zeitpunkt des „Systemabsturzes“ (hier der Zeitpunkt der FlashCopy) offen waren. Anhand der zugehörigen Journaleinträge wird für alle offenen Commit-Zyklen ein entsprechender Rollback gefahren. Damit ist sichergestellt, dass die Daten aus Datenbanksicht konsistent sind.
Um den Zeitbedarf dieses Rollbacks zu minimieren, kann der Befehl CHGASPACT verwendet werden. Ein CHGASPACT OPTION(*SUSPEND) „hält“ die Datenbank und das IFS an. Das heißt – es wird versucht, alle offenen Transaktionen auf eine Commit-Grenze zu bringen. Neue Transaktionen können nicht gestartet werden. Außerdem wird der Inhalt des Hauptspeichers auf die Platten geschrieben. Als zusätzlicher Parameter kann ein Zeitfenster angegeben werden, das festlegt, wie lange das System für diese Aktivitäten „angehalten“ werden soll. Ist der CHGASPACT innerhalb dieses Zeitfensters erfolgreich (alle offenen Transaktionen sind beendet und der Hauptspeicher wurde auf Platte geschrieben), so kann anschließend eine Flash- Copy gezogen werden, der beim Aktivieren keine Rollback-Operationen erfordert. Anschließend wird über ein CHGASPACT OPTION(*RESUME) der Zugriff auf Datenbank und IFS wieder freigegeben und neue Transaktionen können gestartet werden. Um diese Funktion zu verwenden, muss eine laufende Anwendung nicht beendet werden – aus Sicht des Endanwenders stellt sich der Vorgang als sehr lange Antwortzeit dar.
Full System FlashCopy oder FlashCopy eines iASP?
Eine FlashCopy kann sowohl für ein komplettes System aufgesetzt werden – als auch für einen Independant Auxiliary Storage Pool (iASP). Dabei sind jedoch einige Unterschiede zu beachten. Die FlashCopy eines kompletten Systems erstellt eine identische Kopie – mit identischer IP-Adresse, identischem Systemnamen usw. Wird diese Systemkopie aktiviert, so muss sichergestellt werden, dass keine Kollisionen mit dem Quellsystem entstehen.
Auch wenn vor dem Erstellen der FlashCopy ein erfolgreicher CHGASPACT durchgeführt wurde – die Datenbank und das IFS also im Zustand „suspended“ sind – so bedeutet das nicht, dass auch das Betriebssystem inaktiv ist. Es kann daher passieren, dass ein IPL der FlashCopy nicht erfolgreich ist – wenn zum Beispiel zum Zeitpunkt der FlashCopy gerade eine Reorganisation des Spoolbereiches lief.

Dieses Problem stellt sich nicht, wenn ein FlashCopy eines iASP erzeugt wird, da sich im iASP keine Objekte befinden, die Bestandteil des Betriebssystems sind. Ein FlashCopy eines iASPs kann an eine zusätzliche LPAR angehängt werden – beim Aktivieren des iASP läuft ebenfalls der Schritt der Datenbankrecovery ab.
Ein weiterer Vorteil bei der Verwendung von iASPs liegt in der Integration zwischen IBM i und dem Storagesystem durch PowerHA. Hier werden CL-Kommandos zur Verfügung gestellt, die den Befehl zum Erstellen einer FlashCopy an das Storagesystem schicken. Wird hingegen für ein komplettes System eine FlashCopy erstellt, so muss dies am StorageSystem passieren. Alternativ können eigene Skripte entwickelt werden oder das Full System FlashCopy Toolkit von IBM Lab Services verwendet werden.
Einsatzmöglichkeiten von FlashCopy
In immer mehr Kundenumfeldern stellt sich heute das Problem, dass kein Zeitfenster für eine Offline- Datensicherung zur Verfügung steht. Hier kann die Verwendung von FlashCopy eine Alternative bieten. Es wird eine FlashCopy erzeugt (entweder vom Gesamtsystem oder von einem iASP) und diese Kopie aktiviert, um anschließend die Datensicherung von dieser Kopie aus zu starten. Dabei ist zu beachten, dass das Originalsystem nichts von dieser Datensicherung weiß. In den Objektbeschreibungen auf dem Originalsystem finden sich keine Informationen über die erfolgte Sicherung. BRMS bietet entsprechende Verfahren, um sowohl bei einer FlashCopy eines Gesamtsystems als auch eines iASPs die entsprechenden Informationen (was wurde auf welche Bänder gesichert, wie sieht die Recovery- Prozedur aus) an das Originalsystem zu übermitteln.
Wird die FlashCopy, die für eine Datensicherung verwendet werden soll, im laufenden Betrieb gezogen, so ist zu beachten, dass beim Aktivieren der FlashCopy eine Datenbank Recovery läuft. Wenn diese Datensicherung zu einem späteren Zeitpunkt zurückgespeichert wird, so erfordert ein Nachfahren von Journaleinträgen (um auf den aktuellen Datenstand zu kommen) einen nicht unerheblichen manuellen Aufwand. Hintergrund ist hier, dass als Startzeitpunkt für das Nachfahren nicht der Journaleintrag der Datensicherung verwendet werden kann – dieser ist in den Journalempfängern des Originalsystems ja gar nicht vorhanden – und der Zeitpunkt der Datensicherung muss in keinster Weise identisch mit dem Zeitpunkt der FlashCopy sein. Auch der Zeitpunkt der FlashCopy ist kein geeigneter, für alle Dateien gültiger Aufsetzpunkt, weil durch die Datenbankrecovery für einzelne Dateien ein Rollback erfolgt ist und damit im Journalempfänger einzelne Einträge vorhanden sind, die zwar vor dem Erzeugen der FlashCopy in das Journal geschrieben wurden, die aber nicht Bestandteil der gesicherten Daten sind. Hier muss für jede Datei, für die beim Aktivieren der FlashCopy ein Rollback erfolgt ist, manuell der Aufsatzpunkt (Zeitpunkt des letzten Commit für diese Datei) gesucht werden und der APYJRNCHG entsprechend aufgesetzt werden. Ein für alle Dateien identischer Aufsetzpunkt ist nur vorhanden, wenn die FlashCopy auf einem komplett beruhigten System erzeugt wurde – beim Aktivieren der FlashCopy also keinerlei Rollback-Aktivitäten entstehen.
Eine weitere Einsatzmöglichkeit von FlashCopy ist die Funktion eines „Rettungsankers“ bei größeren Softwareänderungen. Dabei wird – möglichst bei ausgeschaltetem System – eine FlashCopy erzeugt, bevor die Softwareänderungen durchgeführt werden. Um sich außerdem gegen den Ausfall des Storagesystems zu schützen, sollte zusätzlich auch immer eine aktuelle Datensicherung zur Verfügung stehen. Stellt man während des Anwendungstests fest, dass die Software-Änderungen nicht erfolgreich waren und auf den Stand vor den erfolgten Änderungen zurückgegangen werden muss, so gibt es dafür zwei unterschiedliche Möglichkeiten. Entweder kann der Zugriff auf das Produktionssystem auf die FlashCopy umgeleitet werden – in diesem Fall kann auf den bereits geänderten Daten noch eine Fehleranalyse erfolgen. Alternativ kann ein FlashCopy Reverse durchgeführt werden. Dabei werden die Daten auf den Quell- Volumes mit den Daten der Ziel- Volumes überschrieben. In beiden Fällen kann der Zugriff auf die Daten innerhalb eines sehr kurzen Zeitfensters zur Verfügung gestellt werden – und so der Zeitaufwand für einen Restore vom Band eingespart werden.
Über die Autorin
Die Autorin Sabine Jordan ist Senior IT Spezialistin bei der IBM Deutschland GmbH und per email erreichbar unter Sabine_ Jordan@de.ibm.com. Sie arbeitet seit 10 Jahren intensiv im Umfeld IBM i und Verfügbarkeit – sowohl in Kundenprojekten als auch bei der Erstellung von Redbooks und als Referentin auf nationalen und internationalen Konferenzen.
Ähnliche Artikel:


